Machine Translation (MT) has long been a daily occurrence in the language industry. Machine Translation Post-Editing (MTPE) is an integral part of many workflows. This saves a lot of time and money – at least when the machine output is good enough.
But this is where the exciting questions start: when can you rely on machine translation? And how do you ensure that your carefully maintained corporate terminology is used correctly and consistently?
Some time ago, these questions led to an idea that later became my master’s thesis. The focus was on two methods to make the post-editing workflow more efficient: Quality Estimation and MT glossaries. Both promise more automation options and better quality – but they also pose a number of challenges in practice.
In this blog post I would like to highlight how quality estimation and MT glossaries work together in an MTPE workflow, where their limits lie and what should be taken into account when using them. And if you ask yourself after reading whether these two methods would also work in your use case, please do not hesitate to get in touch with us – we will be happy to help you implement an MT workflow that brings real added value.
Quality Estimation: do humans really have to get involved?
Quality Estimation (QE) is not a new concept as a method to reduce potential translation effort. Modern QE approaches are based on vector-based evaluation metrics such as COMET. Unlike classical metrics such as BLEU or TER, which compare word and character matches in particular, they evaluate the semantic similarity of texts.
This is made possible by language models that have been trained with human quality assessments. This also resulted in reference-free metrics that can be used to assess the quality of machine translation without human reference translation – even for texts that have never been translated before.
In practice, Quality Estimation can help to decide whether human post-editing is necessary at all. Especially with less critical content, it can be estimated in advance whether the pure MT output is sufficient or whether an additional review would be useful.
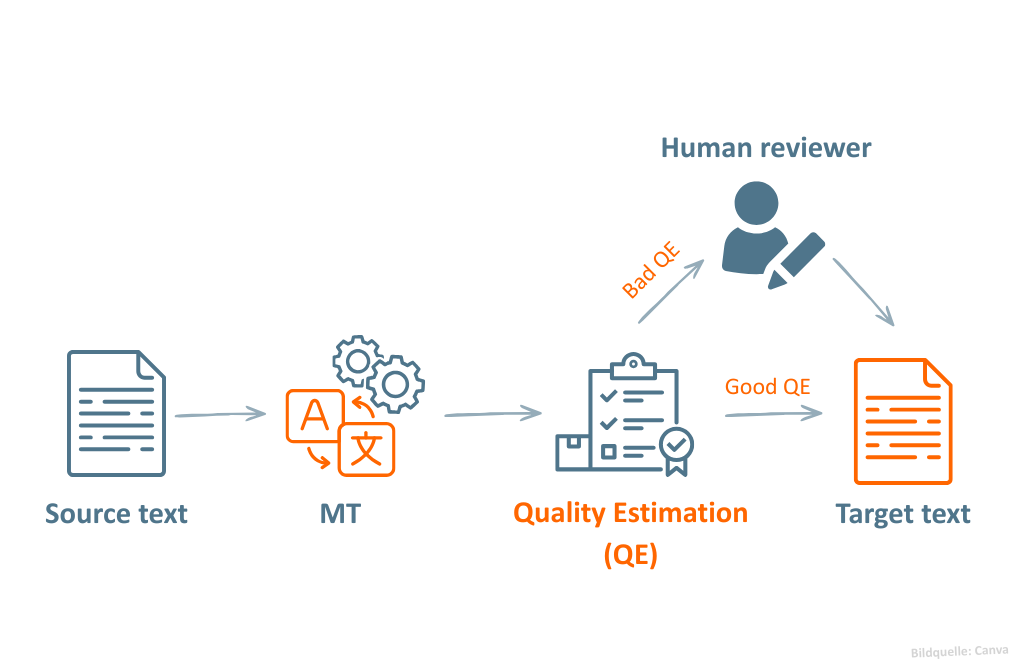
The figure above shows an example of the use of Quality Estimation in an MTPE workflow. After machine translation, a QE model evaluates the quality of the MT output based on a quality score. Depending on the result, the text is either used directly or forwarded to human post-editors for review.
The boom in Large Language Models (LLMs) has also changed Quality Estimation. Instead of specially trained, smaller models, powerful LLMs are often used today. At the same time, the process does not necessarily end with a poor QE score: LLMs can additionally perform automatic post-editing (APE) and then re-evaluate the translation. In some cases, further quality problems can be solved automatically and additional costs can be saved.
Can you trust Quality Estimation?
The method initially sounds very charming: with just one additional step in the workflow, a clear risk picture can be created and a sound decision basis can be gained. But how reliable are such scores really?
As I noted in my master thesis, the quality of the assessment strongly depends on the underlying models and training data. The decisive factor here is how well these are matched to the respective use case. For example, if translation memories or terminology databases are taken into account, the models provide much more relevant results.
Different text types and language directions also play an important role. A model that reliably evaluates marketing translations does not automatically work just as well for legal texts or software documentation. In addition, the results are often much more stable for widely used languages such as English or Spanish than for languages with a smaller database, such as Czech or Maltese.
Despite all progress, Quality Estimation remains a purely machine-based method. For critical content in particular, the estimation should therefore always be additionally reviewed by a person.
Implementing Quality Estimation can be complex, especially in large organizations with large volumes of data and different types of content. We are happy to support you in building an efficient and reliable MT workflow!
MT Glossaries: how correct terminology can become a problem for MT
MT glossaries are another exciting approach, which my colleague Sophia has already explained in more detail in her blog post. Simply put, these are terminology lists that are directly integrated into the MT workflow to ensure that certain terms are automatically translated correctly.
Unlike traditional translation glossaries in translation management systems, MT glossaries do not serve as a help for translators, but intervene directly in machine translation output. For this purpose, they usually consist of unique naming pairs – that is, a source language and a preferred target language naming. Modern NMT systems can often even automatically adapt these terms to the grammatical context.
MT glossaries offer great potential, especially in the MTPE workflow: They help to keep terminology consistent and ensure that corporate language is used already in MT output. In combination with Quality Estimation, this may significantly reduce the effort required for terminology research and subsequent corrections.
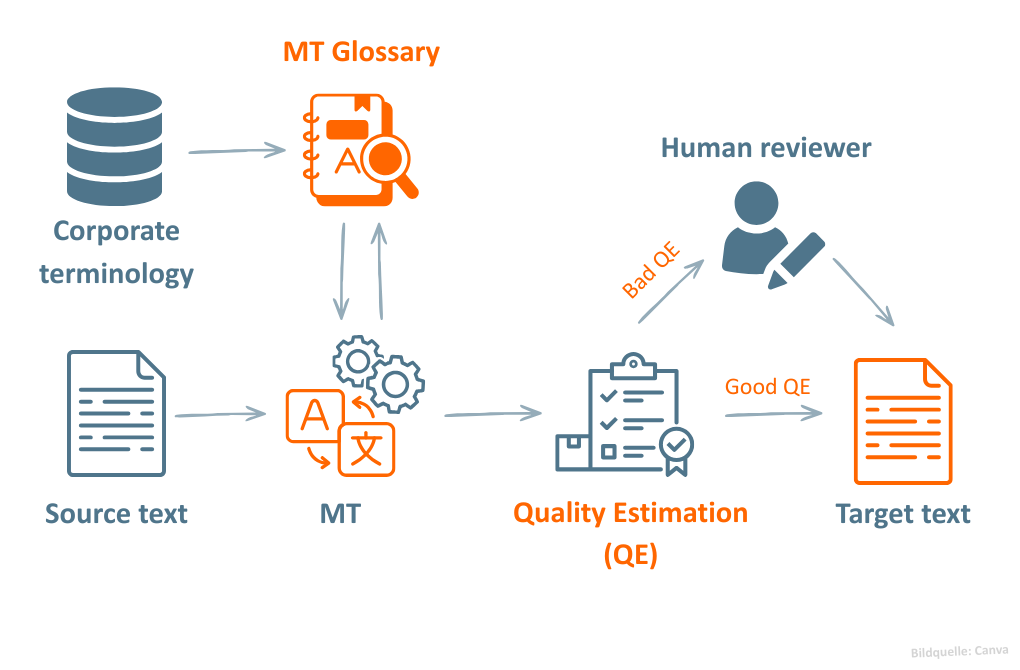
The figure shows an example of how MT glossaries and Quality Estimation can be combined in a common MT workflow. Company-specific glossaries are already used during machine translation to ensure the desired terminology. The quality of the MT output generated is then automatically estimated using Quality Estimation.
However, practice shows that even with MT glossaries, some things can go wrong. Although existing corporate terminology may seem like the ideal basis for glossaries at first glance, terminology databases and MT glossaries differ fundamentally: terminology databases are structured in a concept-oriented way, while glossaries are naming-oriented.
For MT glossaries, therefore, it is particularly appropriate to use unique terms with only one preferred translation if possible. Nouns, proper names and acronyms are particularly useful, as they can usually be used consistently and in a context-independent manner.
It should also be noted that MT glossaries are not static lists. They evolve along with corporate terminology and need to be maintained and updated on a regular basis. A clearly defined care process as early as possible helps to efficiently incorporate changes into the glossaries.
And last but not least, without a solid terminological basis, the creation of MT glossaries will quickly become complicated and unsuccessful. Therefore, it is often worthwhile to first build up your own terminology in a structured manner before integrating glossaries into the MT workflow.
Conclusion
Quality estimation and MT glossaries are both powerful methods for making existing MT workflows more efficient with manageable effort and creating potential savings. But like any technology, they also need to be carefully treated: otherwise incorrect MT output can slip through the QE filter or terms can be replaced by inappropriate equivalents.
It is therefore worth thinking about potential obstacles early on and planning the deployment well. Whether you would like to learn more about Quality Estimation and MT glossaries or would like to optimize your existing MT workflow, blc will be happy to support you in implementing your ideas.
Sounds good?
Then get in touch!