Modern language models can imitate human behaviour in impressive ways, generating coherent and linguistically clean texts in many languages. However, this makes it difficult to evaluate and compare such systems because differences often lie in the more subtle details, such as the exact word choice or stylistic and textual properties.
Traditional automated evaluation methods, such as BLEU, ROUGE, or even the more elaborate BERTScore, are not always sufficient to reliably evaluate machine-generated texts and compare competing systems, particularly due to the fact that these metrics estimate text quality based on semantic overlap with reference texts.
What happens, however, if all systems have high semantic similarity to the reference? How do you decide which one is the best? And what do you do if there are no reference texts at all?
What is LLM-as-a-judge?
There is a solution to all these issues that may sound a little crazy – using LLMs to evaluate other language models. This method is gaining more and more traction and may already be much more present than we are even aware of. I’ll explain that in a little more detail.
First of all, a few key facts about this amazing idea:
The strengths of LLM-as-a-judge
Since 2023, “LLM-as-a-judge” has become increasingly popular. It is used to evaluate all kinds of machine-generated texts. The new paradigm became known through a study by Zheng et al., which showed that GPT-4 was able to provide evaluations for question-answer systems comparable to those of an unskilled human worker (“crowd worker”). Since then, the process has received a lot of attention in the AI world, as it could contribute to further quality leaps in the NLP area. It not only solves the aforementioned problems of previous automatic evaluation procedures, but can also offer a much cheaper and more robust alternative to human evaluation. It is scalable and flexible for different tasks, combining many of the benefits of previous automated and manual evaluation methods.
The potentials even go far beyond system evaluation. LLM-as-a-judge also opens the door to new approaches for further improving the output of chat-optimised systems such as ChatGPT. For example, the LLM evaluators can provide feedback on the basis of which the system evaluates and improves itself iteratively and continuously during training or even on-the-fly (while generating the answer for the user). This enables the guidance of internal argumentation processes and optimisation of the final output to the user. Although this may still be a pie in the sky, it is also possible that LLM-as-a-judge is already being used in applications of well-known AI providers. After all, we do not know the exact methods used in the background.
Design decisions for LLM-as-a-judge
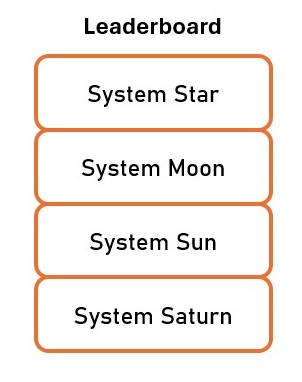
Let’s now focus on system evaluation with LLM-as-a-judge. Let’s assume we want LLM-as-a-judge to compare machine translation systems and to create a ranking of how good each system is, as shown in the image on the left. How does it work? And what do you have to keep in mind while using this approach?
First of all, the question arises as to whether reference translations are available. If this is the case, we can hand these references over to the judge LLM and instruct it to take them into account during the evaluation.
Furthermore, we must decide which basic scoring procedure we want to use. There are two basic setups which are shown in figures below.
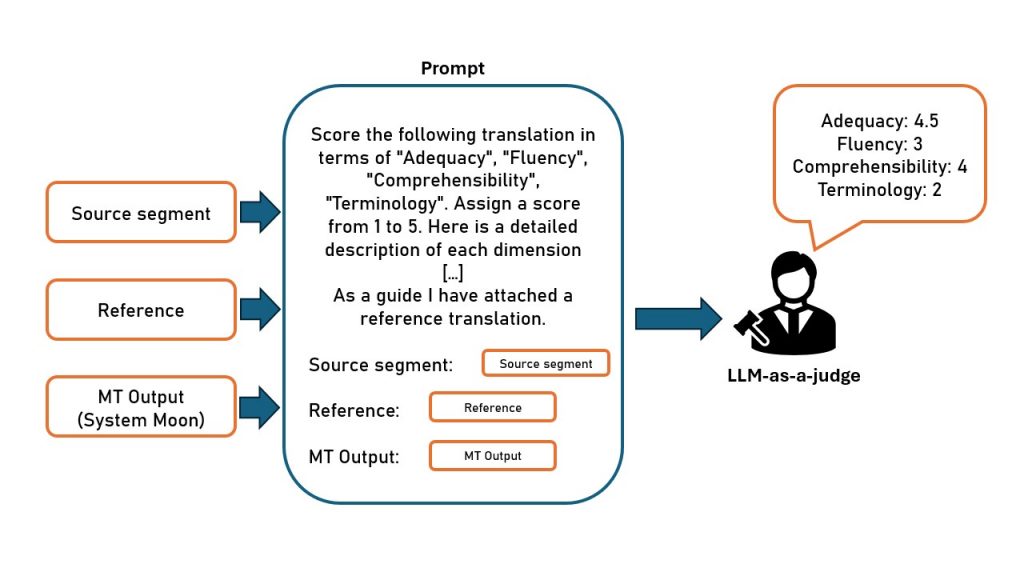
Absolute Scoring
In the first case, LLM-as-a-judge evaluates individual MT outputs. For example, points are awarded in different categories such as “comprehensibility”, “accuracy” and “terminology”. By aggregating the averages, it is easy to calculate a ranking of different systems. However, you can also create individual rankings for each evaluation criterion.
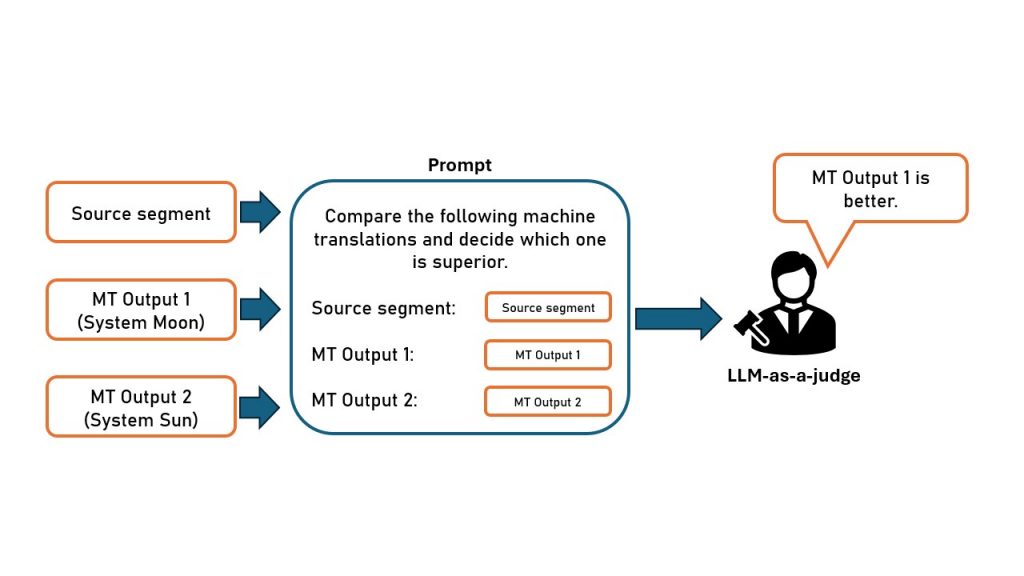
Relative Scoring
Alternatively, LLM-as-a-judge can be used to compare the outputs of several MT systems, arranging them according to quality. This works best with pairwise comparisons: the LLM evaluator is given the segment in the source language, the reference translation if available, and the translations of exactly two MT systems. The judge must then choose which is superior. When enough pairwise comparisons are performed, a ranking can be generated using a scoring method, the so-called “Elo rating system”.
Both methods – pairwise comparisons and individual evaluations – have advantages and disadvantages. The most suitable procedure depends on the specific application.
The quality of LLM-as-a-judge is also strongly dependent on the prompt. There is already some research that compares different prompting strategies in order to obtain the most accurate and reliable evaluations possible. Other studies deal with the idea of finetuning LLMs specifically for the role of the evaluator. This work also produced promising results. We are looking forward to further developments in this area.
What are the problems with LLM-as-a-judge?
The biggest known limitation of LLM-as-a-judge is model bias. Specifically, researchers have found that LLMs tend to over-rely on superficial textual properties, such as response length, when assessing overall text quality. Most of the biases discovered so far are less relevant for MT evaluation, because current studies are mainly concerned with question-answer systems. Nevertheless, biases should be considered in the design of the evaluation system using LLM-as-a-judge. Especially in pairwise comparisons, LLM-as-a-judge often has a preference for a particular answer position, for example, it more often chooses the translation that is presented at the first position in the prompt. However, there are also already methods that minimise the influence of these biases.
Conclusion
LLM-as-a-judge is an exciting and promising new approach to evaluate and compare generative language models. Much is still unknown, which is why special care is needed when this method is used. However, it has incredible potential to run large-scale evaluations for little money and optimise systems.
Interested? If you have any questions about this or other evaluation procedures, please do not hesitate to get in touch with us. We are happy to help!