
Wie Übersetzungsqualität mit smarter Terminologieintegration verbessert werden kann – eine blc Success Story
Ausgangssituation
Wenn maschinelle Übersetzung auf Fachsprache trifft
Maschinelle Übersetzung (MÜ) gehört heute in vielen Unternehmen zum Alltag – auch in der hochregulierten Pharmaindustrie. Doch was passiert, wenn die MÜ auf komplexe, produktspezifische Terminologie trifft? Wenn das Training eigener Modelle nicht mehr ausreicht?
Ein europäisches Pharmaunternehmen stand genau vor dieser Herausforderung: Eine umfangreiche, gut gepflegte Terminologiedatenbank war vorhanden – aber nicht mit der maschinellen Übersetzung verbunden. Die Folge: Fehlende Konsistenz, hoher Post-Editing-Aufwand und somit zusätzliche Kosten.
Gemeinsam mit blc wurde ein Konzept entwickelt, um die bestehende Terminologie über Glossare in das MÜ-System zu integrieren.
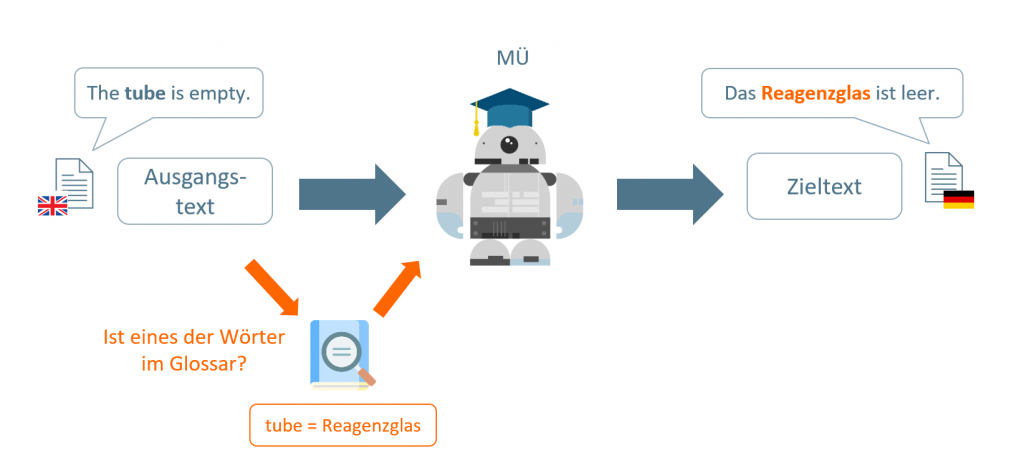
Wie funktionieren MÜ-Glossare?
Ein MÜ-Glossar ist im Grunde eine Wörterliste mit festen Übersetzungszuordnungen, die von der Maschine während des Übersetzungsprozesses berücksichtigt werden. Das System prüft, ob ein Wort im Ausgangstext im Glossar enthalten ist und ersetzt es dann automatisch durch die festgelegte Zielsprachenterminologie, unabhängig vom Kontext. Anders als beim Training eines KI-Modells, das mithilfe von neuronalen Methoden komplexe Zusammenhänge lernt, greift das Glossar regelbasiert und sofort ein: Es überschreibt die Standardübersetzung, ohne das Modell (neu) zu trainieren. Damit eignet sich diese Methode besonders gut, um produkt- oder markenspezifische Terminologie konsistent zu halten – und zwar über verschiedene Projekte, Sprachen und Systeme hinweg.
Herangehensweise
Termbank vs. Glossar: Same same but different
Während die Terminologiedatenbank begriffsorientiert arbeitet, also mehrere synonyme Benennungen zu Einträgen zusammenfasst, die dann auf verschiedenen Ebenen Metadaten und Kontextinformationen enthalten, braucht ein MÜ-Glossar benennungsorientierte 1:1-Zuordnungen. Diese Vereinfachung ist notwendig, damit die MÜ die Fachbegriffe in jedem Kontext korrekt erkennt und einsetzt. Das bedeutet jedoch, dass die bestehende Terminologiedatenbank nicht einfach unbearbeitet hinterlegt werden kann.
Der Prozess für die Erstellung von Glossaren
Zu Beginn des Projekts wurden die über 60 Sprachpaare in Sprachpaar-Batches aufgeteilt und priorisiert. Batch für Batch arbeitete sich blc durch die Terminologie und folgte dabei einem wiederholbaren Prozess:

Best Practices: Was ein gutes MÜ-Glossar ausmacht
Im Projekt haben sich für die Validierung unter anderem folgende Best Practices bewährt:
- Einfach halten: Je größer das Glossar ist, desto höher der Rechenaufwand für jede Übersetzungsanfrage. Das Glossar sollte so umfangreich wie nötig, aber dabei so einfach wie möglich gehalten werden.
- Ambiguität vermeiden: Ist eine Benennung mehrdeutig, sollte sie nicht im Glossar stehen.
- Fokus auf geeignete Wortarten: Substantive, Produktnamen und Akronyme eigenen sich gut, Verben oder komplexe Phrasen eher weniger.
Terminologie ist dynamisch – und die Glossare müssen es auch sein
Der Clou an der Sache: Terminologie lebt. Produkte verändern sich, Märkte kommen hinzu, neue Begriffe entstehen. Damit die MÜ-Glossare damit Schritt halten können, wurde ein Pflegeprozess etabliert, den der Kunde selbst durchführen kann. Dabei werden regelmäßig Deltas über einen Filter in der Terminologiedatenbank ermittelt, validiert und in neue Glossarversionen überführt.

Ergebnis
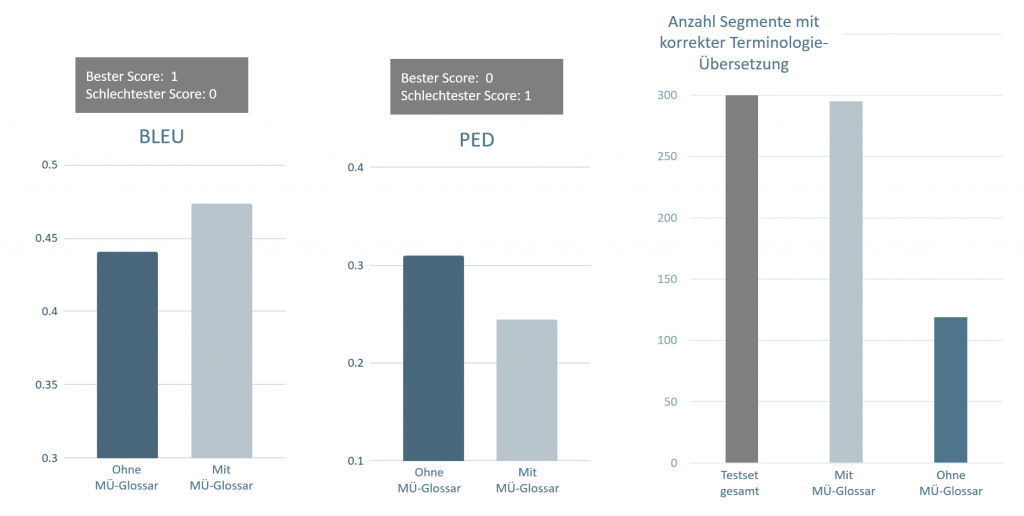
Messbar bessere Übersetzungsqualität
Wie groß der Einfluss der Glossare ist, zeigte eine Evaluation für die Sprachrichtung Englisch > Deutsch.
300 Sätze wurden einmal mit, einmal ohne MÜ-Glossar übersetzt – und anschließend automatisch und manuell ausgewertet.
Das Ergebnis: Bei der Übersetzung mit MÜ-Glossar…
Ausblick – Was kommt als Nächstes?
Aktuell werden Glossare für 17 Sprachrichtungen produktiv genutzt, vier weitere folgen bis Ende des Jahres. Die nächsten Schritte sind bereits definiert und in Arbeit:
Die bestehende Terminologiedatenbank wird dahingehend optimiert, dass über das Datenmodell die Glossar-Validität sowie die benötigten 1:1-Entsprechungen abgebildet werden können – trotz Begriffsorientierung.
So ist eine direkte API-Anbindung an das MÜ-System in Zukunft möglich. blc und der Kunde sind dazu schon mit dem MÜ-Systemhersteller im Gespräch.
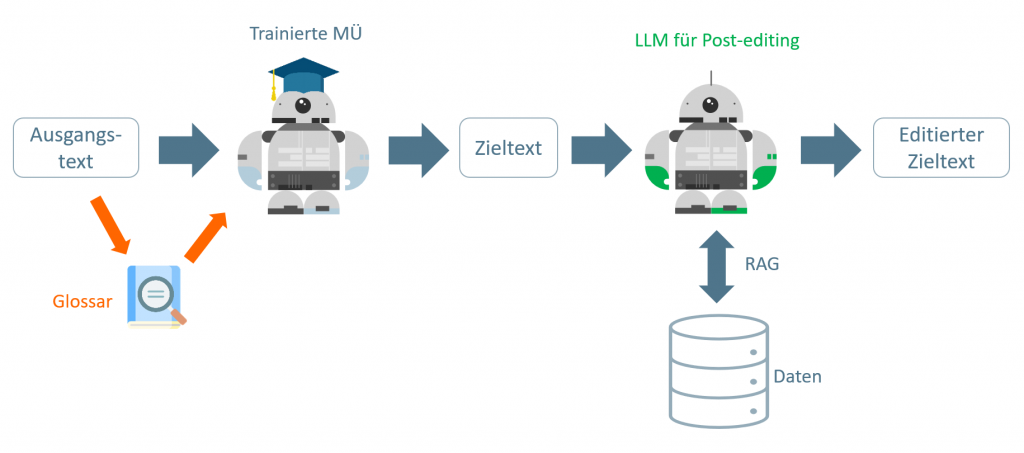
Eine Zukunftspotenzial ist zudem die Nutzung der Terminologie für LLMs und RAG-Szenarien, um KI-Systeme mit terminologisch sauberem Wissen zu versorgen. Langfristig kann so ein kombinierter Ansatz aus trainierter MÜ, Glossaren und Terminologiedatenbank entstehen.
Fazit: Terminologieintegration ist ein entscheidender Erfolgsfaktor für die Qualität (KI-gestützter) Übersetzungen. Wer vorhandene Terminologieressourcen konsequent nutzt, erreicht nicht nur konsistentere Ergebnisse, sondern auch nachhaltig effizientere Übersetzungsprozesse.
Sie wollen mehr Details zu dieser Success Story erfahren? Dieser Use Case wird auf der tekom 2025 vorgestellt. Kommen Sie vorbei oder schreiben Sie uns direkt an!
")

