
Large Language Models sind spätestens seit der Veröffentlichung von ChatGPT in aller Munde. Es ist erstaunlich, wie gut die modernen AI-Modelle mit Sprache umgehen können. Aber wie kommt es überhaupt, dass ein Computer Sprache „versteht“?
Dafür muss zunächst die Bedeutung eines Worts quantifizierbar und für Maschinen lesbar gemacht werden. Hier kommen Word Embeddings ins Spiel: Word Embeddings (WE) sind ein innovatives Verfahren aus dem Bereich Natural Language Processing (NLP), bei dem Wörter abhängig von ihrer Bedeutung als Vektoren in einen hoch-dimensionalen Vektorraum eingebettet werden (deshalb auch Word Embedding, dt. „Worteinbettung“). Dabei wird sowohl der Vorgang als auch das Produkt WE genannt.
Vom Wort zum Vektor
Tatsächlich liegt der innovativen Technik ein recht alter Ansatz zugrunde. Das Unterfangen, Bedeutungen messbar zu machen, beruht auf der sogenannten Distributionshypothese, die erstmals in den 1950er-Jahren von den Linguisten Martin Joos, Zellig Harris und John Rupert Firth formuliert wurde. Sie besagt, dass Wörter, die in ähnlichem Kontext auftreten, in der Regel ähnliche Bedeutungen haben. Der Bedeutungsunterschied zwischen zwei Wörtern entspricht dabei ungefähr dem Unterschied in ihrem Umfeld.
„If A and B have some environments in common and some not […] we say that they have different meanings, the amount of meaning difference corresponding roughly to the amount of difference in their environments.”
Um die Bedeutung eines Worts zu bestimmen, kann also sein Kontext herangezogen werden. Die Beziehungen zwischen einem Wort und seinen Kontextwörtern können dabei helfen, zu ermitteln, ob zwei Wörter besonders wahrscheinlich gemeinsam auftreten.
WE-Algorithmen lernen die Vektorisierung durch neuronale Netze aus der Verteilung der Wörter im Trainingstext. Im einfachsten Fall repräsentiert dabei jede Dimension oder Achse einen Kontext und die Koordinate auf dieser Achse repräsentiert die Häufigkeit des Vorkommens mit diesem Kontext. Das würde aber auch bedeuten, dass ein Vektor eine Dimension pro einzigartiges Wort im Trainingstext hat – und somit das Koordinatensystem eine Achse. Bei großen Trainingskorpora werden hier schnell Dimensionen im 100.000er-Bereich erreicht. Um Rechenleistung zu sparen, wird in der Realität deshalb meist eine Dimensionsreduktion vorgenommen.
Vektoren – und dann?
Das Ergebnis erlaubt einen Vergleich zwischen den einzelnen Wörtern aufgrund ihrer Position im Vektorraum. Typischerweise bilden ähnliche Wörter semantische Cluster in diesem Koordinatensystem (siehe Abbildung 1).
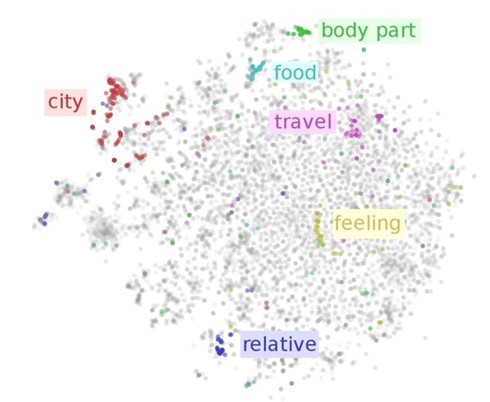
Außerdem bildet die Position der einzelnen Wortvektoren ihre Beziehung zueinander ab, z.B. grammatischer oder semantischer Art. Man kann dann die Grundlagen der linearen Algebra auf die Vektoren anwenden, um Wortähnlichkeiten und Analogien zu untersuchen. Basierend auf Abbildung 2 könnte man „Rom“ – „Italien“ + „Spanien“ ≈ „Madrid“ als Rechenbeispiel heranziehen.
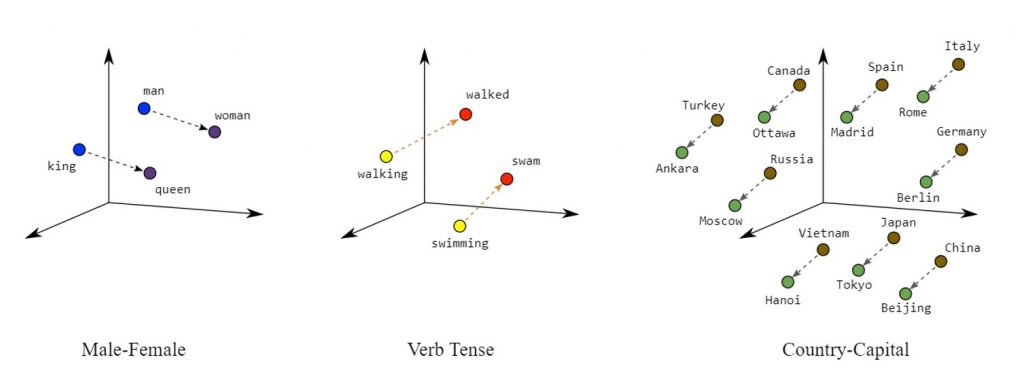
Mithilfe dieser Vektordarstellung eines Vokabulars kann ein Computer nun Sprache „verstehen“ und sogar selbst produzieren, indem die Wahrscheinlichkeit aufeinanderfolgender Wörter anhand ihrer Vektordarstellungen berechnet wird.
Achtung: Schubladendenken!
Wir wissen nun: WE trainieren auf Kontexten und bilden die Bedeutungen ab, die im Ausgangstext vorhanden sind. Es finden sich deshalb kulturelle oder sprachliche Merkmale in den WE wieder, wenn diese im Trainingskorpus überrepräsentiert sind. Wird ein WE-Algorithmus z.B. auf den Harry Potter-Büchern trainiert, so wird man eine andere Bedeutung von Sport bekommen, als wenn der Input aktuelle Zeitungsartikel aus Deutschland enthält. Dieses Phänomen kann absichtlich für die eigenen Zwecke genutzt werden, beispielsweise um einem unternehmensinternen Chatbot die Corporate Language anzueignen. Aber gerade bei allgemeinsprachlichen Modellen ist Vorsicht geboten: Sind im Trainingskorpus Texte enthalten, die Stereotype oder Vorurteile enthalten, so landen diese zwangsläufig im Output.
Die Zukunft ist dynamisch
Die ersten WE-Algorithmen, die Anfang der 2010er-Jahre auf den Markt kamen, z.B. Word2Vec, GloVE oder FastText, sind statisch. Bei statischen WE gibt es genau eine Vektorrepräsentation pro Wort. Damit geht jedoch das Problem einher, wie mit ambigen Wörtern umgegangen wird. Beispielsweise hat das Wort „Flügel“ in den Sätzen „Der Vogel hat Flügel“ und „Der Pianist spielt auf dem Flügel“ eine ganz unterschiedliche Bedeutung.
Moderne WE-Verfahren, sogenannte Contextualized Word Embeddings, zu denen z.B. ELMO oder BERT zählen, können als neue Generation der WE betrachtet werden, bei denen sich die Einbettung eines Worts je nach Kontext dynamisch verändert. Heutzutage haben die dynamischen Modelle die statischen (in den meisten Use Cases) weitestgehend abgelöst.
Aufgrund ihrer Nützlichkeit und Leistungsfähigkeit kommen (Contextualized) WE in vielen Anwendungsbereichen des NLP, bei denen Wort- oder Textbedeutung eine Rolle spielen, zum Einsatz. Sie liegen den meisten Maschine-Learning-Programmen und Large Language Models zugrunde. Die Vektorisierung ist dabei aber normalerweise nur ein Schritt in einer längeren Pipeline.
Interesse geweckt? Auf der Terminologie³ am 27. Und 28.06. in Karlsruhe werden in einem kurzen Impulsvortrag ein paar WE-Modelle gegenübergestellt.
Word Embeddings in der Terminologiearbeit?
Auch in der Terminologiearbeit kann man Word Embeddings nutzen! Wenn Sie sich dafür interessieren, wie WE beim Aufbau von Concept Maps und Ontologien unterstützen können, seien Sie gespannt auf unseren Workshop bei Terminologie³! Dort wird außerdem der Vektorisierungsprozess Schritt für Schritt erklärt und selbst umgesetzt.



