Large language models have been on everyone’s lips since the release of ChatGPT at the latest. It is amazing how well modern AI models can handle language. But how is it that a computer “understands” language?
To do this, the meaning of a word must first be made quantifiable and readable by machines. Word Embeddings come into play here: Word Embeddings (WE) are an innovative method in the field of Natural Language Processing (NLP) in which words are embedded in a high-dimensional vector space depending on their meaning as vectors (hence Word Embedding). Both the process and the product are called WE.
From word to vector
In fact, this innovative technology is based on a rather old approach. The attempt to make meanings measurable is based on the so-called distribution hypothesis, which was first formulated in the 1950s by linguists Martin Joos, Zellig Harris and John Rupert Firth. It says that words that occur in similar contexts usually have similar meanings. The difference in meaning between two words is approximately the same as the difference in their environment.
“If A and B have some environments in common and some not […] we say that they have different meanings, the amount of meaning difference corresponding roughly to the amount of difference in their environments.”
In order to determine the meaning of a word, its context can be used. The relationships between a word and its contextual words can help determine whether two words are most likely to occur together.
WE algorithms learn vectorization through neural networks from the distribution of words in the training text. In the simplest case, each dimension or axis represents a context, and the coordinate on that axis represents the frequency of occurrence with that context. But this would also mean that a vector has one dimension per unique word in the training text – and thus the coordinate system has one axis. For large training corpora, dimensions in the 100,000s range are quickly achieved. In order to save computing power, therefore in reality is usually carried out a dimension reduction.
Vectors – and what’s next?
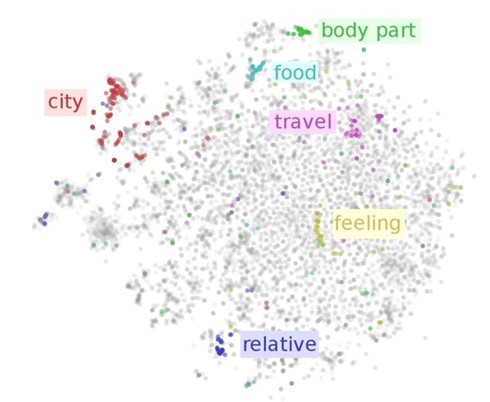
The result allows a comparison between the individual words based on their position in the vector space. Typically, similar words form semantic clusters in this coordinate system (see Figure 1).
Figure 1: Semantic clusters in vector space. Source: Rudder.io 2016.
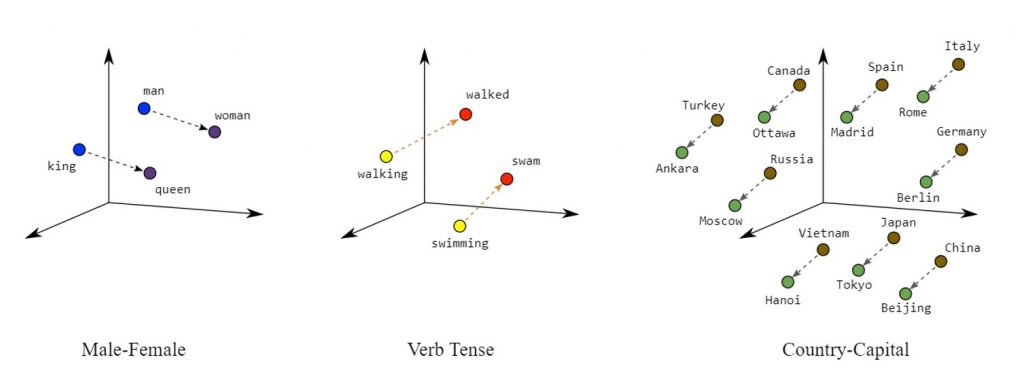
In addition, the position of the individual word vectors reflects their grammatical or semantical relationship to each other. You can then apply the basics of linear algebra to the vectors to examine word similarities and analogies. Based on Figure 2, one could use “Rome” – “Italy” + “Spain” ≈ “Madrid” as an example calculation.
Using this vector representation of a vocabulary, a computer can now “understand” and even generate language by calculating the probability of consecutive words based on their vector representations.
Thinking in boxes!
We now know: WE train on contexts and map the meanings that are present in the source text. Therefore, cultural or linguistic characteristics are reflected in the WE if they are over-represented in the training body. For example, if a WE algorithm is trained on the Harry Potter books, sports will have a different meaning than if the input contains current newspaper articles from Germany. This phenomenon can be used intentionally for one’s own purposes, for example, to acquire the corporate language from an internal corporate chatbot. But especially with general language models, caution is required: If texts containing stereotypes or prejudices are included in the training body, they inevitably end up in the output.
The future is dynamic
The first WE algorithms that were introduced in the early 2010s, e.g. Word2Vec, Glove or FastText, are static. For static WE, there is exactly one vector representation per word. However, this is accompanied by the problem of how to deal with ambiguous words. For example, the word “bat” in the sentences “the bat sleeps in the cave” and “John uses his bat” has a very different meaning.
Modern WE processes, so-called Contextualized Word Embeddings, which include e.g. ELMO or BERT, can be regarded as a new generation of WE, in which the embedding of a word changes dynamically depending on the context. Today, dynamic models have largely replaced static models (in most use cases).
Due to their usefulness and performance, (contextualized) WE are used in many areas of application of the NLP, where word or text meaning play a role. They are the basis for most machine learning programs and large language models. But vectorization is usually just a step in a longer pipeline.
Word Embeddings in terminology work?
Word Embeddings can also be used in terminology work! If you are interested in how WE can help build concept maps and ontologies, be sure to attend our workshop at Terminology³! There, the vectorization process is explained step by step and implemented together.
Last March I joined blc as a master's student. The goal: to write a master's thesis on the synergies of terminology and ontologies by October. And even though I am no longer a master's student, but now support blc in the area of translation and terminology management on a full-time basis, the topic is still with me. After all, it was my constant companion for 6 to 7 months.
So in this blog, I will tell you a little more about the subject and why it is so important. First of all, synergies between terminology and ontology are not only something for the theoreticians among us. No, you can also use these synergies efficiently for yourself in day-to-day work.
Terms such as “Ontology” and “Semantic Web” are still a new territory for many. However, in today's information society, which is characterized by digitalization and automation, these terms are gaining more and more importance. We would like to show you why ontologies are becoming increasingly significant as the next logical step after the introduction of efficient terminology management and the establishment of a consistent terminology collection.
But what are ontologies? What do they look like and how can they be represented? And what is their purpose - especially regarding their use in the Semantic Web?
Diese Website verwendet teilweise so genannte Cookies. Cookies richten auf Ihrem Rechner keinen Schaden an und enthalten keine Viren. Cookies dienen dazu, unser Angebot nutzerfreundlicher, effektiver und sicherer zu machen. Cookies sind kleine Textdateien, die auf Ihrem Rechner abgelegt werden und die Ihr Browser speichert.
Die meisten der von uns verwendeten Cookies sind so genannte „Session-Cookies“. Sie werden nach Ende Ihres Besuchs automatisch gelöscht. Andere Cookies bleiben auf Ihrem Endgerät gespeichert, bis Sie diese löschen. Diese Cookies ermöglichen es uns, Ihren Browser beim nächsten Besuch wiederzuerkennen.
Sie können Ihren Browser so einstellen, dass Sie über das Setzen von Cookies informiert werden und Cookies nur im Einzelfall erlauben, die Annahme von Cookies für bestimmte Fälle oder generell ausschließen sowie das automatische Löschen der Cookies beim Schließen des Browser aktivieren. Bei der Deaktivierung von Cookies kann die Funktionalität dieser Website eingeschränkt sein.
Funktional
Always active
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.