


Trainingsdaten mithilfe von Datenbereinigung für die Maschinelle Übersetzung vorzubereiten, kann manchmal wie eine Mammutaufgabe erscheinen. Ganz unwahr ist das nicht – denn in der Praxis bringen die Vielzahl möglicher „Verunreinigungen“ von Daten und hohe Datenvolumen immer wieder Herausforderungen mit sich. Warum es sich trotzdem in jedem Fall lohnt, diese Zeit zu investieren und wie Automatisierung dabei helfen kann, sich große Teile dieser Arbeit zu sparen, soll in diesem Blog aufgezeigt werden.
Warum ist die Bereinigung von Daten notwendig?
Wer maschinelle Übersetzung (kurz MÜ) verwenden möchte, die an den eigenen Übersetzungsprozess angepasst ist und sich der unternehmenseigenen Terminologie bedient, der kann bei einem der vielfältigen Anbieter maßgeschneiderte Übersetzungs-Engines in Anspruch nehmen und diese mit eigenen Daten trainieren. Trainingsdaten im Kontext von MÜ sind in der Regel alignierte Satzpaare. Darunter versteht man eine Menge von Sätzen mit eindeutiger Zuordnung zwischen Ausgangssatz und Übersetzung in der jeweiligen Zielsprache.
Das Training erfordert eine ausreichend große Menge an Trainingsdaten, deren Qualität möglichst dem gewünschten Resultat entspricht. Ist das nicht der Fall, sprich enthalten die Trainingsdaten viele oder systematische Fehler, so leidet der positive Trainingseffekt stark. Es ist sogar möglich, dass die MÜ systematisch fehlerhafte Muster lernt. Genau hier kommt die Datenbereinigung ins Spiel – sie kann viele problematische Muster erkennen und vor dem Training beseitigen oder korrigieren.
Welche Probleme mit der Datenqualität können vorkommen?
Die Liste möglicher „Verunreinigungen“ von MÜ-Trainingsdaten, bei denen Datenbereinigung Abhilfe leisten kann, ist lang. Um dem Leser einen Eindruck zu verschaffen, sind im Folgenden einige gängige Probleme mit extrahierten Trainingsdaten aufgelistet:
- Unvollständige Daten, bspw. ist nur die Ausgangssprache vorhanden, aber die Zielsprache leer. In anderen Fällen ist das Zielsegment nur die Übersetzung eines Teiles des Ausgangssegments (etwa erklärende Zusätze in Klammern, die nicht übersetzt werden)
- Personenbezogenen Daten: Aus Datenschutz- und Sicherheitsgründen bedenkliche Informationen wie Adressen, Telefonnummern, Kontodaten etc.
- Übersetzungen, die unerwünschte oder veraltete Terminologie verwenden: MÜ kann die falsche Terminologie erlernen, bspw. veraltete Produkt- oder Bereichsnamen
- Beschädigte oder schwer lesbare Segmente, bspw. durch fehlerhafte Kodierung, fehlende Leerzeichen/Zeilenumbrüche etc.
- Uneinheitliche Daten, bspw. teilweise mehrere Sätze in einem Segment oder uneinheitliche Schreibweisen für Währungs- oder Datumseinheiten
Ebenso ist es möglich, dass ein Segment an sich unproblematisch ist, aber es im Kontext der Gesamtmenge problematisch wird, etwa:
- Mehrfaches Vorkommen identischer Segmente: eine hohe Anzahl identischer Segmente kann zu einer ungewünschten Gewichtung der entsprechenden Inhalte führen
- Nicht-repräsentative Daten: Überrepräsentation bzw. Unterrepräsentation von Domänen aufgrund der Verfügbarkeit von Daten kann zu einem unausgeglichenen Training der Engines führen
- Falsche Sprachzuordnung in den Metadaten, bspw. zielsprachliche Inhalte im Ausgangstext (oder umgekehrt), die zu Fehlern im gelernten MÜ-Modell führen. Bei domänenspezifischem Training auch: einer falschen Domäne zugeordnete Daten
Was lässt sich mit Datenbereinigung gegen solche Probleme tun und wie läuft diese ab?
In einem ersten Schritt müssen potentiell problematische Segmente erkannt und markiert werden. Hierbei ist es praktisch unumgänglich, Software zu verwenden, die diesen Prozess automatisiert: in der Praxis können Trainingsdaten Hunderttausende oder sogar Millionen von Satzpaaren umfassen, wobei es nach oben kaum eine Grenze gibt. Das automatisierte Erkennen von problematischen Segmenten kann je nach Art des Problems sehr elementar oder äußerst komplex sein. Mehrfach vorkommende identische Segmente zu erkennen und markieren, lässt sich beispielsweise in wenigen Zeilen Code erledigen. Personen- oder Unternehmensnamen zum Zwecke der Anonymisierung in beliebigen Sätzen zu erkennen, erfordert hingegen fortgeschrittene Methoden und in der Regel die Zuhilfenahme externer Softwarepakete.
Für das weitere Verfahren mit problematischen Segmenten kann man im Wesentlichen zwei Ansätze unterscheiden: das Löschen oder das Reparieren dieser Segmente. Da das Trainingsvolumen für einen maximalen Trainingseffekt möglichst groß bleiben sollte, ist die Reparatur problematischer Segmente ihrer Entfernung immer vorzuziehen. Es sollte jedoch geprüft werden, ob dies praktikabel ist und ob nach der Reparatur für das MT-Training brauchbare Segmente zurückbleiben.
Beispiele für Reparaturen an problematischen Segmenten
Fälschlicherweise im Text verbliebene Code-Fragmente können automatisiert erkannt und gelöscht oder mithilfe von Named Entity Recognition erkannte Personennamen mit Platzhaltern überschrieben werden. Wenn konkrete Vorgaben für eine gewünschte Terminologie existieren (etwa in Form einer Terminologie-Datenbank) und zudem bekannt ist, welche Terme unerwünschterweise häufig verwendet werden, so ist es auch möglich, diese Fälle zu identifizieren und ggf. manuell zu bereinigen. Automatische Ersetzungen sind zwar möglich, aber mit Vorsicht zu genießen und bedürfen stets einer manuellen Überprüfung.
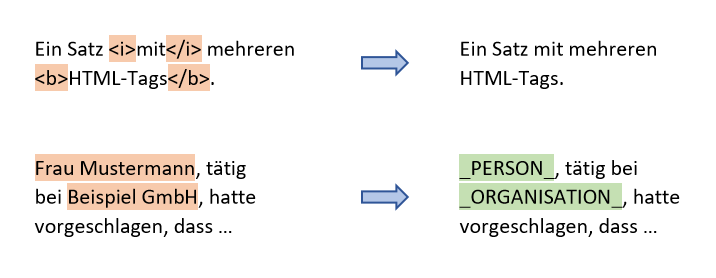
In andere Fällen – etwa durch andere Bereinigungsschritte entstandene leere Segmente – bleibt dagegen als Option nur noch das Löschen übrig. Gut durchdachte, automatisierte Entscheidungsalgorithmen können dabei helfen, die richtige Balance aus Mindestanforderungen an die Segmentqualität und bestmöglichem Erhalt des Trainingsvolumens zu finden.
Fazit
Datenbereinigung ist ein beachtlicher Teil des Aufwands für das Training von MÜ-Engines. Sie erfordert häufig kreative und innovative Methoden zur Automatisierung. Auch wenn die Bereinigung das Trainingsvolumen in der Regel verringert, lässt sich mit ihr deutlich besser die Qualität des MÜ Inputs und die letztendlich erlernten Muster regulieren. Die für die Festlegung der Anforderungen, Überprüfung und anschließende Bereinigung von Daten benötigte Zeit ist daher in jedem Fall eine lohnende Investition. Sie ermöglicht es, dass die MÜ klare und möglichst fehlerfreie Muster lernt. Die hierdurch gesteigerte Output-Qualität vermeidet somit später erheblichen Mehraufwand beim Post-Editing. Darüber hinaus liefert die Analyse bei der Datenbereinigung wichtige Erkenntnisse über die Datenqualität und offenbart Optimierungspotentiale für den Übersetzungsprozess.
Es ist von zentraler Bedeutung, ein für das individuelle Trainingsszenario ausgewogenes Gleichgewicht aus Qualitätsanforderungen und Trainingsvolumen zu finden. Hier lässt sich eine Analogie zum menschlichen Lernen ziehen: Möchte man einen komplexen Sachverhalt richtig verstehen, so sollte man diesen einerseits an ausreichend verschiedenen Beispielen wiederholen. Andererseits sollten die behandelten Beispiele aber auch größtenteils schlüssig sein, um die korrekten Muster dauerhaft zu festigen.


