
Last week, my colleague Rebecca Gasper explained why terminology cleansing is so relevant to the practical use of termbases. In today’s blog, I would like to talk a little about the technical background and common approaches from everyday terminology cleanups.
The basics
Terminology databases help organizations establish consistent rules for terminology to be used and ensure compliance with them using technical tools. They are usually structured hierarchically:
- The entry level is the parent semantic concept for collecting related terms.
- The language level groups the terms within a concept by language.
- The term level includes the terms for an entry in a language (such as preferred terms, prohibited terms, synonyms, etc.).
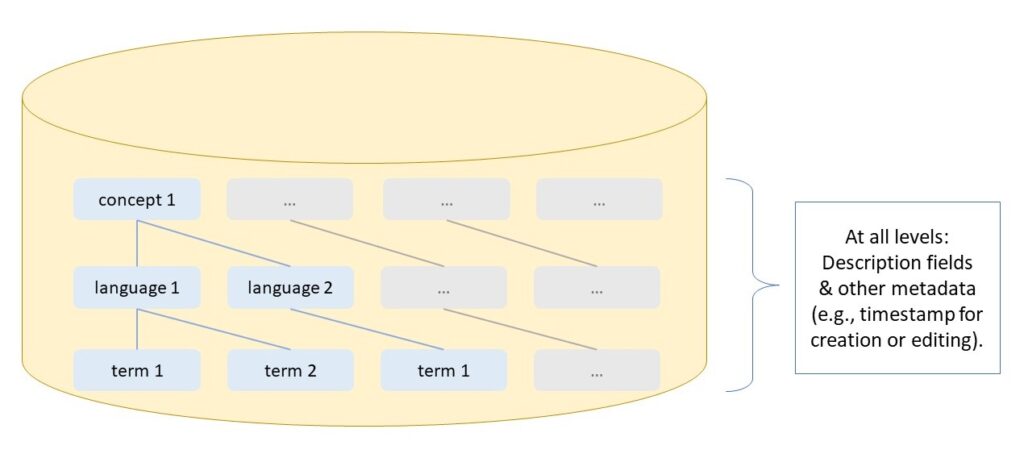
Terminology database schemes define the specific composition of the permitted description fields and metadata at each of these levels.
In addition, companies generally specify exactly which rule catalog the terminology content is to be entered into the database defined in accordance with this scheme, as more complex requirements cannot always be fully represented in the scheme.
Why do termbases need to be cleaned up?
Terminology changes over time, allowing users to customize their termbases. This can include changes to terms and their translations, description fields such as the usage status, or the scheme or internal rule catalog.
When many such changes occur, the potential for errors increases over time:
-
- Existing rules are not always correctly understood or adhered to.
-
- Unsightly conventions or workarounds arise, e.g. the misuse of description fields for internal processes.
-
- New terms are inserted as a new entry, although an old entry with a possibly changed usage status is already in the database.
-
- Entries that are no longer relevant or are no longer desired for any other reason are not always deleted.
-
- Defined procedures change, but data assets that were still created according to old conventions remain.
The size of termbases, which in total can be in the hundreds of thousands of terms, and each of these terms can also have countless description fields, makes databases cumbersome and very difficult to overlook. Many of the problematic patterns mentioned above are often very repetitive, but due to the size of the database, they require enormous manual effort to be fixed in the standard program interface. This is often hardly realistically feasible for terminologists.
How do you clean up a terminology database?
To cope with the scale of such historically grown problems, automated or semi-automated terminology database cleanup can help. These cleanups can be distinguished in two main ways:
Substantive terminology cleanup
Substantive terminology cleansing involves first automatically examining an existing termbase for potentially problematic patterns and then manually reviewing it. Such problematic patterns can be, for example, unwanted characters, grammatical forms, abbreviations, or related terms that are not marked as an entry group.
It allows terminologists to focus and pre-filter explicitly on the relevant parts of the terminology database.
This makes it easier to always proceed in the same way when dealing with similar problem patterns. In addition, an intermediate format can be used that is better suited for sequentially processing problems than the source and target formats. These benefits significantly reduce the time required to manually clean up terminology compared to cleanup without prior problem analysis.
If there are larger amounts of company-specific continuous text (such as in large translation memories or website texts) regardless of the terminology database, the “real” usage frequencies of the terminology in the terminology database can also be statistically calculated. Alternatively, terminology extraction can identify corporate terminology that is common in actual use but not in the terminology database.
However, the automatic analysis of problematic patterns and terminology usage can also be performed independently of subsequent cleansing. This can be useful for a comprehensive analysis of the quality of the existing terminology, for example.
Structural terminology cleanup
Structural terminology database cleanup automatically modifies the terminology database directly in the original format. A fully automated implementation of changes of all kinds is always possible if this is defined according to a clear rule-based pattern. Such clear patterns can be, for example:
-
- Rename description fields or language labels
-
- Unconditional or conditional deletion of certain description fields
-
- Change content based on mapping rules
-
- Move fields between metadata detail levels
-
- Rule-based creation of fields with normalized content
-
- Flat-rate or rule-based pseudonymization of fields with GDPR-relevant content
-
- Merge or divide termbases
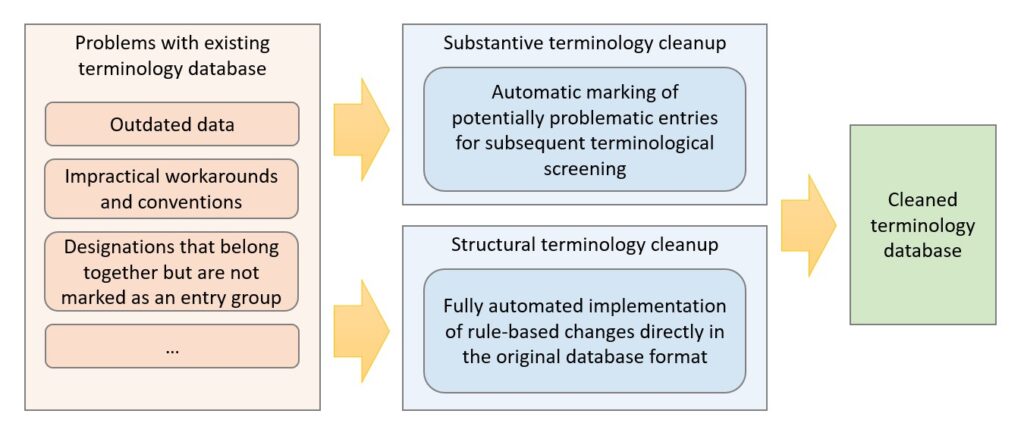
Depending on requirements, the content or structural terminology database cleanup can be applied independently of each other or both.
For best results, the initial terminology management situation in the company should always be analyzed and the solution tailored to the needs of the company.
Conclusion
Terminology databases are powerful tools for documenting and applying corporate terminology. To ensure that the benefits of these tools are maintained even if problems have accumulated over time, terminology cleanups can help.
If you would like to know more about the topic or if you are wondering how terminology cleanups or terminology management can be used in your company, please do not hesitate to contact us .



