Moderne Sprachmodelle können auf beeindruckende Weise menschliches Verhalten nachahmen und in vielen Sprachen kohärente und sprachlich sauber formulierte Texte generieren. Dies erschwert jedoch die Evaluation und Vergleiche solcher Systeme, weil Unterschiede nun häufig in den subtileren Details liegen, wie zum Beispiel in der genauen Wortwahl oder stilistischen textuellen Eigenschaften.
Traditionelle, automatisierte Evaluationsmethoden wie BLEU, ROUGE oder sogar der elaboriertere BERTScore reichen nicht mehr immer aus, um maschinell generierte Texte zuverlässig auszuwerten und konkurrierende Systeme miteinander vergleichen zu können. Dies liegt insbesondere daran, dass diese Metriken Textqualität anhand vom semantischen Überlapp mit Referenztexten abschätzt. Was passiert jedoch, wenn alle Systeme hohe semantische Ähnlichkeit mit der Referenz aufweisen? Wie entscheidet man dann, welches das Beste ist? Und was tut man, wenn es gar keine Referenztexte gibt?
Was ist LLM-as-a-judge?
Für all diese Fragen gibt es eine Lösung, die vielleicht ein wenig verrückt klingt – LLMs nutzen, um andere Sprachmodelle zu bewerten. Die Methode erhält immer mehr Aufwind und ist womöglich bereits viel präsenter, als uns überhaupt bewusst ist. Das erkläre ich gleich noch etwas genauer. Erstmal einige Eckdaten zu dieser erstaunlichen Idee:
Die Stärken von LLM-as-a-judge
Seit 2023 wird „LLM-as-a-judge“ immer beliebter. Es wird eingesetzt, um alle möglichen maschinell generierten Texte zu bewerten. Bekannt wurde das neue Paradigma durch eine Studie von Zheng et al., in der gezeigt wurde, dass GPT-4 für Frage-Antwort-Systeme Evaluationen liefern konnte, die mit denen einer unqualifizierten menschlichen Arbeitskraft („Crowd-Worker“) vergleichbar sind. Seither bekommt das Verfahren in der KI-Welt viel Aufmerksamkeit, da es zu weiteren Qualitätssprüngen im NLP-Bereich beitragen könnte. Es löst nämlich nicht nur die oben-beschriebenen Probleme früherer automatischer Evaluationsverfahren, es könnte auch eine viel günstigere und robustere Alternative zur Humanevaluation bieten. Es ist skalierbar und flexibel für verschiedene Aufgaben anpassbar, wodurch es viele Vorteile von früheren automatischen und manuellen Verfahren kombiniert.
Die Potentiale gehen sogar weit über die Systemevaluation hinaus. LLM-as-a-judge öffnet auch die Tür für neue Verfahren, um die Ausgaben von Chat-optimierten Systemen wie ChatGPT weiter zu verbessern. Beispielsweise können die LLM-Evaluatoren Feedback liefern, auf dessen Basis sich ein das System während des Trainings oder sogar on-the-fly (während es die Antwort für den Benutzer schreibt) iterativ und kontinuierlich selbst bewertet und verbessert. So können interne Argumentationsprozesse geleitet und die finale Ausgabe an den Benutzer optimiert werden. Das mag zwar weitgehend noch Zukunftsmusik sein, da wir aber nicht genau wissen, welche Verfahren bekannte Anbieter von KI-Assistenten im Hintergrund verwenden, ist es durchaus möglich, dass LLM-as-a-judge in solchen Anwendungen bereits zum Einsatz kommt.
Designentscheidungen bei LLM-as-a-judge
Lasst uns den Fokus nun wieder auf Systemevaluation mit LLM-as-a-judge lenken. Nehmen wir mal an, wir wollen LLM-as-a-judge verwenden, um Machine-Translation-Systeme zu vergleichen und eine Rangliste zu erstellen, welches System wie gut ist, wie im Bild links. Wie geht das? Und was muss man dabei beachten?
Zunächst stellt sich die Frage, ob Referenzübersetzungen vorliegen. Ist dies der Fall, können wir diese dem LLM-as-a-judge mit übergeben und es anweisen, sie bei der Bewertung zu berücksichtigen.
Desweitern müssen wir entscheiden, welches grundlegende Bewertungsverfahren wir nutzen wollen. Es gibt zwei grundlegende Verfahren, die in Bildern unten visualisiert sind.
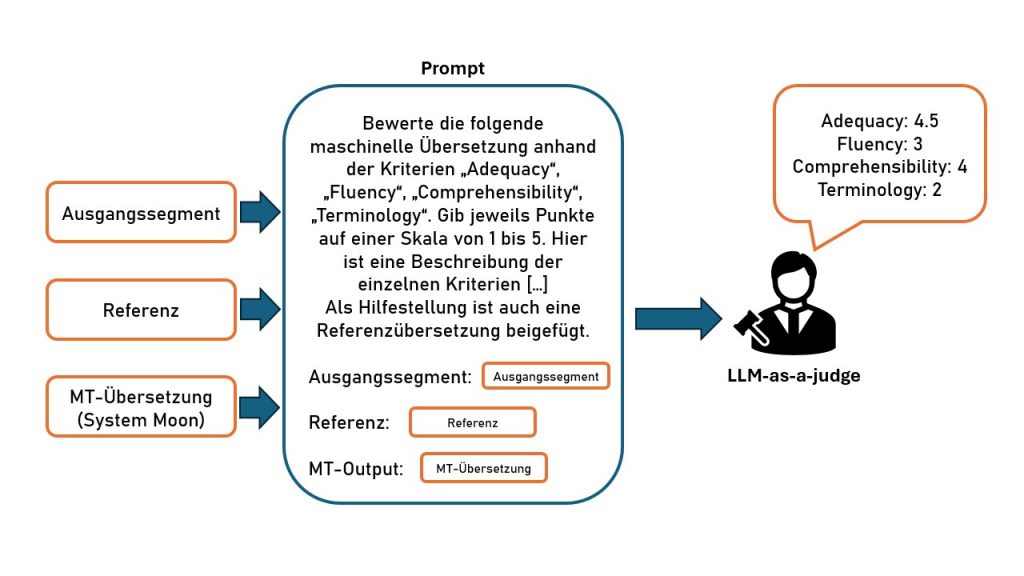
Absolute Bewertung
Beim ersten lässt man LLM-as-a-judge einzelne MT-Outputs bewerten. Dabei werden zum Beispiel Punkte in verschiedenen Kategorien wie „Verständlichkeit“, „Genauigkeit“ und „Terminologie“ vergeben. Wenn man die Durchschnittswerte aggregiert, lässt sich so leicht eine Rangliste verschiedener Systeme errechnen. Man kann aber auch einzelne Ranglisten für jedes Bewertungskriterium erstellen.
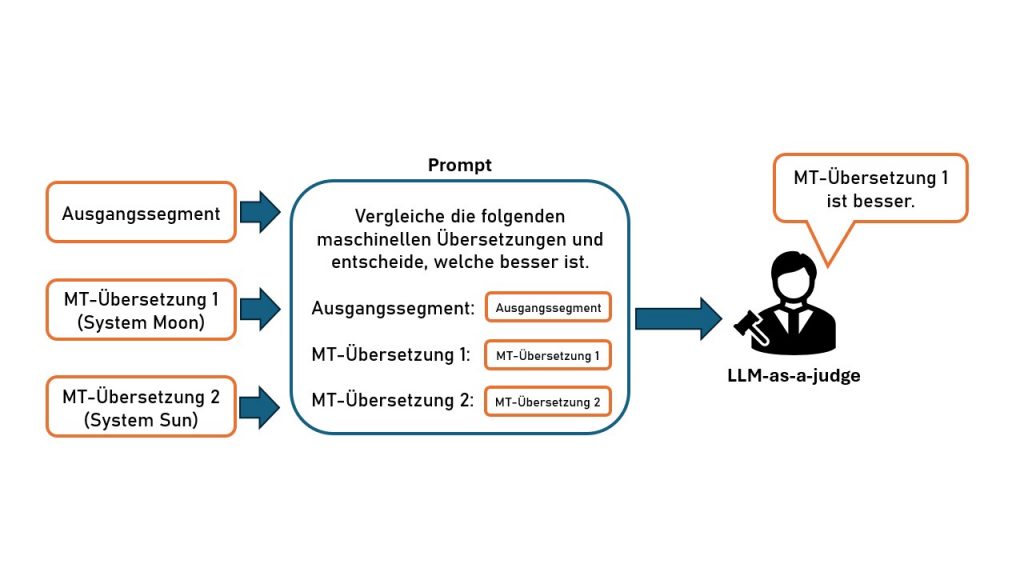
Relative Bewertung
Alternativ kann man mit LLM-as-a-judge die Ausgaben mehrere MT-Systeme miteinander vergleichen und nach Qualität ordnen lassen. Am besten funktioniert das mit paarweisen Vergleichen: Man gibt dem LLM Evaluator das Segment in der Ausgangssprache, gegebenenfalls die Referenzübersetzung und die Übersetzungen von genau zwei MT-Systemen. Der Juror soll dann wählen, welche besser ist. Führt man genügend solcher paarweisen Vergleiche durch, kann man mit einem bestimmten Bepunktungsverfahren, dem sogenannten „Elo-Rating-System“ eine Rangliste generieren.
Beide Methoden – paarweise Vergleiche und einzelne Evaluationen – haben Vor- und Nachteile. Welches Verfahren sich am besten eignet, hängt von der spezifischen Anwendung ab.
Die Qualität von LLM-as-a-judge ist auch stark vom Prompt abhängig. Hier gibt es auch bereits einige Forschung, die verschiedene Prompting-Strategien vergleicht, um möglichst genau und zuverlässige Bewertungsergebnisse zu erhalten. Andere Studien beschäftigen sich mit der Idee, LLMs speziell für die Rolle des Evaluators zu finetunen. Auch diese Arbeiten lieferten vielversprechende Ergebnisse. Wir sind gespannt auf weitere Entwicklungen in diesem Bereich.
Was sind die Probleme mit LLM-as-a-judge?
Die größte bekannte Einschränkung von LLM-as-a-judge sind Biases („Voreingenommenheiten“). Konkret haben Forscher gefunden, dass LLMs Tendenzen aufweisen, Textqualität zu stark an oberflächlichen textuellen Eigenschaften, wie zum Beispiel der Antwortlänge festzumachen. Für MT-Bewertung sind die meisten der bisher entdeckten Biases weniger relevant, weil sich aktuelle Studien hauptsächlich mit Frage-Antwort-Systemen beschäftigen. Trotzdem sollten Biases beim Design des Evaluationssystems mit LLM-as-a-judge berücksichtigt werden. Vor allem bei paarweisen Vergleichen hat LLM-as-a-judge oft eine Präferenz für eine bestimmte Antwortposition, zum Beispiel wählt es häufiger die Übersetzung, die an der ersten Stelle im Prompt präsentiert wird. Hier gibt es jedoch bereits Methoden, die die Einflüsse dieser Biases minimieren.
Fazit
LLM-as-a-judge ist ein spannender und vielversprechender neuer Ansatz, um generative Sprachmodelle zu evaluieren und miteinander zu vergleichen. Vieles ist noch nicht vollständig erforscht, weshalb besondere Sorgfalt geboten ist, wenn man diese Methode einsetzen möchte. Sie birgt jedoch unglaubliches Potential, großflächige Evaluationen für wenig Geld ausführen zu können, um Systeme zu optimieren.
Interesse geweckt? Falls Sie Fragen zu diesem oder anderen Evaluationsverfahren haben, melden Sie sich gerne. Wir helfen gerne weiter.