Maschinelle Übersetzung (MT) ist längst Alltag in der Sprachindustrie. Machine Translation Post-Editing (MTPE) ist aus vielen Workflows nicht mehr wegzudenken. Das spart enorm Zeit und Kosten – zumindest dann, wenn der maschinelle Output gut genug ist.
Doch genau hier beginnen die spannenden Fragen: Wann kann man sich auf maschinelle Übersetzungen verlassen? Und wie stellt man sicher, dass die sorgfältig gepflegte Unternehmensterminologie korrekt und konsistent verwendet wird?
Aus diesen Fragen entstand vor einiger Zeit eine Idee, die später zu meiner Masterarbeit geworden ist. Im Fokus standen dabei zwei Methoden, die den Post-Editing-Workflow effizienter machen sollen: Quality Estimation und MT-Glossare. Beide versprechen mehr Automatisierungsmöglichkeiten und bessere Qualität – bringen in der Praxis aber auch einige Herausforderungen mit sich.
In diesem Blog-Beitrag möchte ich beleuchten, wie Quality Estimation und MT-Glossare im Zusammenspiel in einem MTPE-Workflow funktionieren, wo ihre Grenzen liegen und worauf man beim Einsatz unbedingt achten sollte. Und falls Sie sich nach dem Lesen fragen, ob diese beiden Methoden auch in Ihrem Use-Case funktionieren würden, kontaktieren Sie uns gerne – wir helfen Ihnen gerne bei der Umsetzung eines MT-Workflows, der einen echten Mehrwert bringt.
Quality Estimation: Muss ein Mensch wirklich ran?
Quality Estimation (QE) ist als Methode zur Reduzierung von Übersetzungsaufwand kein neues Konzept. Moderne QE-Ansätze basieren auf vektorbasierten Evaluierungsmetriken wie COMET. Anders als klassische Metriken wie BLEU oder TER, die vor allem Wort- und Zeichenübereinstimmungen vergleichen, bewerten sie die semantische Ähnlichkeit von Texten.
Möglich wird das durch Sprachmodelle, die mit menschlichen Qualitätsbewertungen trainiert wurden. Dadurch entstanden auch referenzfreie Metriken, mit denen sich die Qualität maschineller Übersetzungen ohne menschliche Referenzübersetzung einschätzen lässt – selbst bei Texten, die zuvor nie übersetzt wurden.
In der Praxis hilft Quality Estimation dabei zu entscheiden, ob menschliches Post-Editing überhaupt notwendig ist. Gerade bei weniger kritischen Inhalten kann so bereits vorab abgeschätzt werden, ob der reine MT-Output ausreichend ist oder ob ein zusätzliches Review sinnvoll wäre.
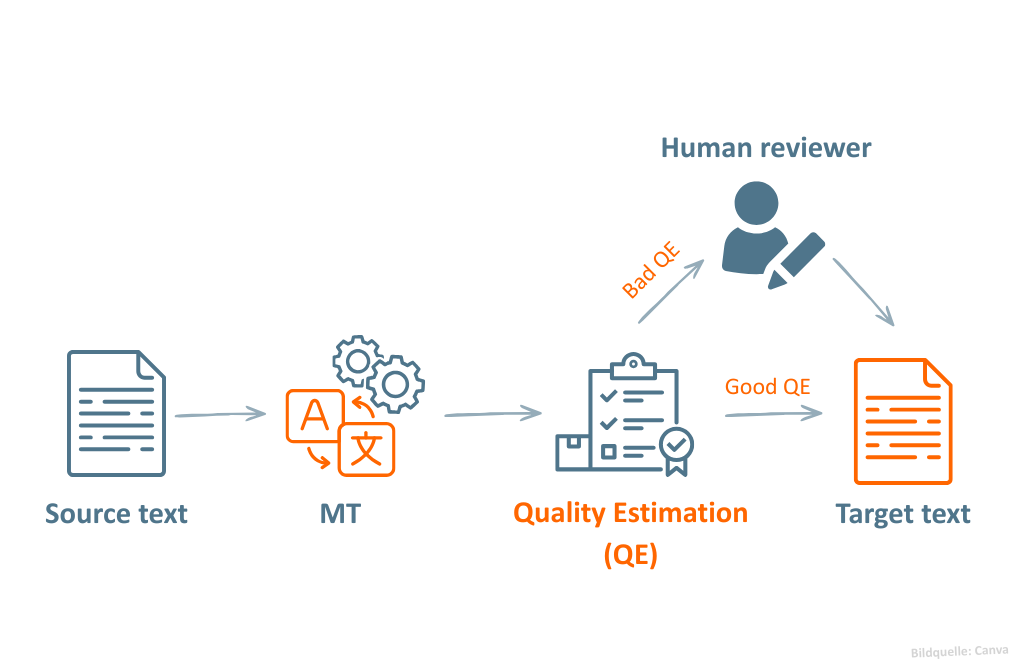
Die Abbildung oben zeigt beispielhaft den Einsatz von Quality Estimation in einem MTPE-Workflow. Nach der maschinellen Übersetzung bewertet ein QE-Modell die Qualität des MT-Outputs anhand eines Qualitäts-Scores. Abhängig vom Ergebnis wird der Text entweder direkt verwendet oder zur Überprüfung an menschliche Post-Editor:innen weitergeleitet.
Der Boom der Large Language Models (LLMs) hat auch die Quality Estimation verändert. Statt speziell trainierter, kleinerer Modelle kommen heute häufig leistungsstarke LLMs zum Einsatz. Gleichzeitig endet der Prozess bei einem schlechten QE-Score nicht mehr zwangsläufig beim menschlichen Review: LLMs können zusätzlich automatisches Post-Editing (APE) durchführen und die Übersetzung anschließend erneut bewerten. So lassen sich in manchen Fällen weitere Qualitätsprobleme automatisch beheben und zusätzliche Kosten einsparen.
Kann man Quality Estimation vertrauen?
Die Methode klingt zunächst sehr charmant: Mit nur einem zusätzlichen Schritt im Workflow lässt sich ein klares Risikobild schaffen und eine fundierte Entscheidungsgrundlage gewinnen. Doch wie zuverlässig sind solche Scores wirklich?
Wie ich in meiner Masterarbeit festgestellt habe, hängt die Qualität der Einschätzung stark von den zugrunde liegenden Modellen und Trainingsdaten ab. Entscheidend ist dabei, wie gut diese auf den jeweiligen Use-Case abgestimmt sind. Werden beispielsweise Translation Memories oder Terminologiedatenbanken berücksichtigt, liefern die Modelle deutlich relevantere Ergebnisse.
Auch unterschiedliche Texttypen und Sprachrichtungen spielen eine wichtige Rolle. Ein Modell, das Marketing-Übersetzungen zuverlässig bewertet, funktioniert nicht automatisch genauso gut für Rechtstexte oder Software-Dokumentation. Zudem sind die Ergebnisse bei weit verbreiteten Sprachen wie Englisch oder Spanisch oft deutlich stabiler als bei Sprachen mit geringerer Datenbasis, etwa Tschechisch oder Maltesisch.
Trotz aller Fortschritte bleibt Quality Estimation eine rein maschinelle Methode. Gerade bei kritischen Inhalten sollte die Bewertung daher immer zusätzlich von einem Menschen überprüft werden.
Die Implementierung von Quality Estimation kann komplex sein – insbesondere in großen Organisationen mit umfangreichen Datenmengen und unterschiedlichen Content-Typen. Wir unterstützen Sie gerne dabei, einen effizienten und zuverlässigen MT-Workflow aufzubauen!
MT-Glossare: Wie richtige Terminologie zum Problem für MT werden kann
MT-Glossare sind ein weiterer spannender Ansatz, den meine Kollegin Sophia bereits ausführlicher in einem eigenen Blog-Beitrag erklärt hat. Vereinfacht gesagt handelt es sich dabei um Terminologielisten, die direkt in den MT-Workflow eingebunden werden, damit bestimmte Begriffe automatisch korrekt übersetzt werden.
Im Gegensatz zu klassischen Übersetzungsglossaren in Translation-Management-Systemen dienen MT-Glossare nicht als Hilfe für Übersetzer:innen, sondern greifen direkt in die maschinelle Übersetzung ein. Dafür bestehen sie in der Regel aus eindeutigen Benennungspaaren – also einer ausgangssprachlichen und einer bevorzugten zielsprachlichen Benennung. Moderne NMT-Systeme können diese Begriffe häufig sogar automatisch an den grammatischen Kontext anpassen.
Gerade im MTPE-Workflow bieten MT-Glossare großes Potenzial: Sie helfen dabei, Terminologie konsistent zu halten und Corporate Language bereits im MT-Output sicherzustellen. In Kombination mit Quality Estimation lassen sich dadurch Aufwand für Terminologierecherche und nachträgliche Korrekturen deutlich reduzieren.
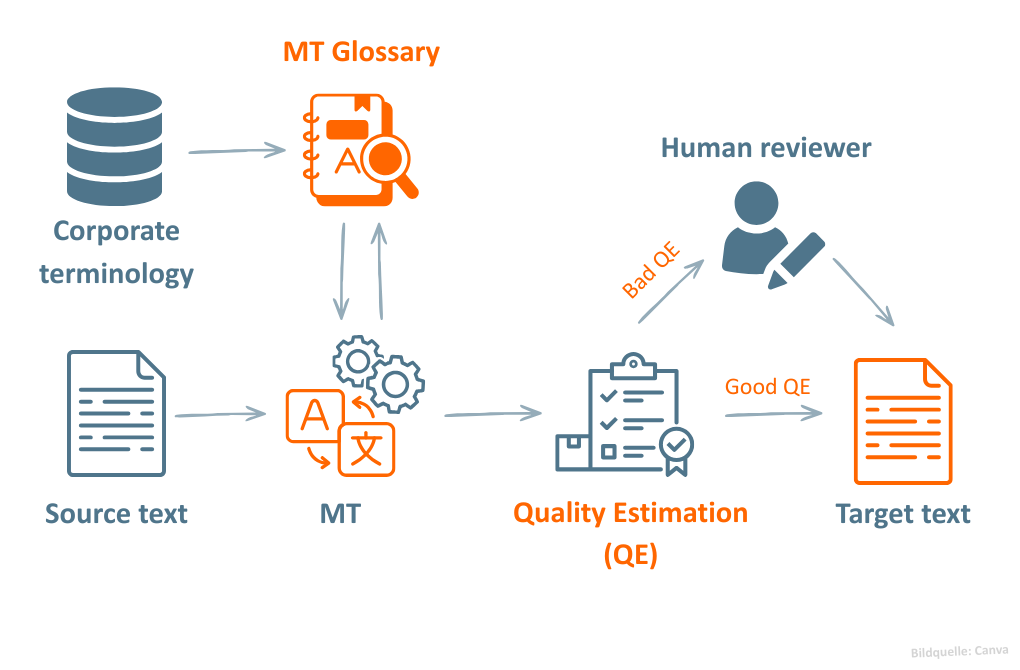
Die Abbildung zeigt beispielhaft, wie sich MT-Glossare und Quality Estimation in einem gemeinsamen MT-Workflow kombinieren lassen. Dabei werden unternehmensspezifische Glossare bereits während der maschinellen Übersetzung eingesetzt, um die gewünschte Terminologie sicherzustellen. Anschließend wird die Qualität des erzeugten MT-Outputs mithilfe von Quality Estimation automatisch eingeschätzt.
Allerdings zeigt die Praxis, dass auch bei MT-Glossaren einiges schief laufen kann. Zwar wirkt bestehende Unternehmensterminologie auf den ersten Blick wie die ideale Grundlage für Glossare, doch terminologische Datenbanken und MT-Glossare unterscheiden sich grundlegend: Terminologiedatenbanken sind begriffsorientiert aufgebaut, Glossare dagegen benennungsorientiert.
Für MT-Glossare eignen sich deshalb vor allem eindeutige Benennungen mit möglichst nur einer bevorzugten Übersetzung. Besonders sinnvoll sind Substantive, Eigennamen und Akronyme, da sie sich meist konsistent und kontextunabhängig verwenden lassen.
Außerdem sollte man bedenken, dass MT-Glossare keine statischen Listen sind. Sie entwickeln sich gemeinsam mit der Unternehmensterminologie weiter und müssen regelmäßig gepflegt und aktualisiert werden. Ein möglichst früh klar definierter Pflegeprozess hilft dabei, Änderungen effizient in die Glossare zu übernehmen.
Und nicht zuletzt gilt: Ohne eine solide terminologische Grundlage wird auch die Erstellung von MT-Glossaren schnell kompliziert und wenig zielführend. Deshalb lohnt es sich oft, zunächst die eigene Terminologie strukturiert aufzubauen, bevor Glossare in den MT-Workflow integriert werden.
Fazit
Quality Estimation und MT-Glossare sind beides mächtigen Methoden, um bestehende MT-Workflows mit überschaubarem Aufwand effizienter zu gestalten und Einsparpotenziale zu schaffen. Doch wie jede Technologie müssen auch sie sorgfältig vorbereitet werden: Sonst können fehlerhafte MT-Ausgaben durch den QE-Filter rutschen oder Benennungen durch unpassende Entsprechungen ersetzt werden.
Deshalb lohnt es sich, mögliche Stolpersteine frühzeitig mitzudenken und den Einsatz gut zu planen. Ob Sie mehr über Quality Estimation und MT-Glossare erfahren möchten oder Ihren bestehenden MT-Workflow optimieren wollen: blc unterstützt Sie gerne bei der Umsetzung Ihrer Ideen.
Klingt gut?
Dann kontaktieren Sie uns direkt!