
Vor 2 Jahren stand die überarbeitete und harmonisierte Datenschutzgrundverordnung (DSGVO) vor der Haustür. Leider konnte sie nicht klingeln, denn Unbekannte hatten bereits die Klingelschilder anonymisiert ;-). Aber Spaß beiseite: Wie sieht es denn heute mit dem Umgang der DSGVO in der Übersetzung aus? In dieser Reihe widmen wir uns dem Thema aus mehreren Blickwinkeln. In diesem Blog erfolgt der Einstieg in die DSGVO und die Besonderheiten für den Übersetzungsprozess…
Privacy Paradox oder der ganz normale Wahnsinn
Zunächst zur Begriffsklärung ein Schweinsgalopp durch die DSGVO: Im Kern dreht sich alles um den guten Gedanken, die persönlichen Rechte der EU-Bürger in Bezug auf ihre personenbezogenen Daten besser zu schützen.
Personenbezogene Daten (PBD) sind alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person beziehen. Unternehmen oder Produkte oder Marken sind demzufolge keine personenbezogenen Daten:

Aufgrund der rasanten technologischen Entwicklung und der Verlagerung vieler Prozesse ins Netz haben PBD vor allem für Online-Plattformen, Apps und Shops unschätzbaren Wert. Viele Menschen wissen gar nicht mehr, wo und vor allem wofür und von wem ihre Daten verwendet werden. Die Angst vor Datenmissbrauch steigt.
In diesem Zusammenhang ist der Begriff des Privacy Paradox gekürt worden: Menschen teilen viele persönliche Informationen, während sie sich gleichzeitig große Sorgen um ihre Privatheit machen.
Pudels Kern: Sechs vernünftige Grundsätze
Die Seele der DSGVO besteht aus sechs Grundsätzen, hier die ersten fünf:
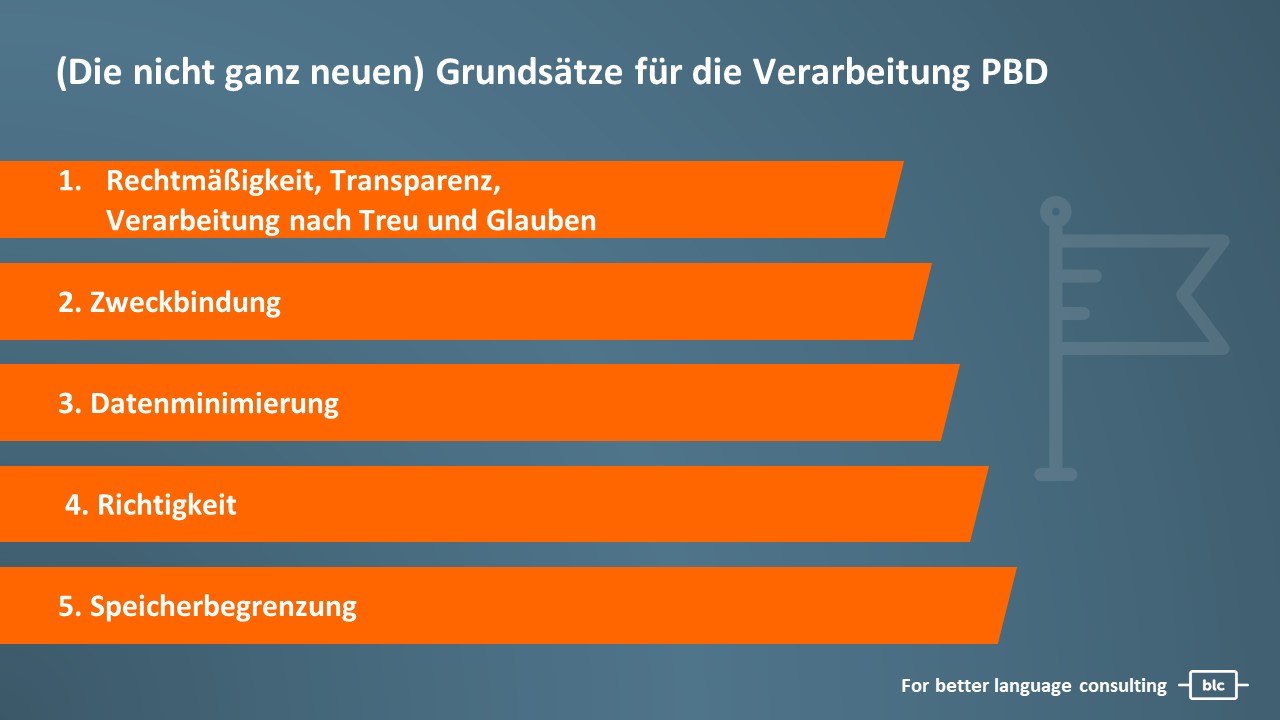
Diese Grundsätze sind eigentlich selbsterklärend, können aber jederzeit in der DSGVO im Detail nachgelesen werden.
Der vor allem für die Betrachtung von Systemen zur Übersetzung wichtige sechste Grundsatz lautet: Integrität und Vertraulichkeit und nennt zwei Paradigmen: Privacy by Design und Privacy by Default:

Im Prinzip bedeutet Privacy by Design nichts anderes, als dass Hersteller ihre Systeme so gestalten sollen, dass die Privatheit der Benutzer und der Schutz der verarbeiteten personenbezogenen Daten von vornherein gegeben ist. Idealerweise sollte demnach bereits im Entwicklungsstadium einer Software daran gedacht werden. Privacy by Default soll dem Privacy-Paradox entgegenwirken, indem Systemhersteller die Basiseinstellungen ihrer Systeme, Webseiten oder Prozesse so gestalten, dass die personenbezogenen Daten (PBD) der Benutzer von Beginn an per Default geschützt werden.
Eine DSGVO-freundliche Systemgestaltung ist das A und O und gilt für alle Systeme, die bei der Verarbeitung personenbezogener Daten eine Rolle spielen:

DSGVO-konforme (Übersetzungs-)Prozesse im Unternehmen
Wie sind denn nun Übersetzungsprozesse und deren technische Umgebungen mit Blick auf die DSGVO zu beurteilen? Das hängt sehr stark davon ab, welche Rolle im Prozess man einnimmt und welche Datenkategorien man betrachtet. Die Datenverantwortlichen, das sind diejenigen im Prozess, die PBD verarbeiten und speichern, müssen sich darum kümmern, dass alle internen und externen Prozesse DSGVO-konform sind. Für Benutzerdaten ist das relativ einfach, denn diese werden meist so gespeichert, dass sie auch wieder gelöscht werden können (auf Verlangen oder durch die Benutzer selbst). Wie aber sieht es mit den Übersetzungsdaten selber aus?
Metadaten, z.B. in Translation Memories, enthalten unter Umständen PBD, die nach einer Weile gelöscht werden müssen. Und dann gibt es ja auch noch die PBD in den Texten selbst. Eins ist aber klar: Der Datenverantwortliche ist immer verantwortlich und muss sich darum kümmern, dass keine Daten zweckentfremdet werden. Wie weit er dafür gehen muss, ist für Übersetzungsprozesse aus unserer Sicht immer noch nicht schlussendlich geklärt.
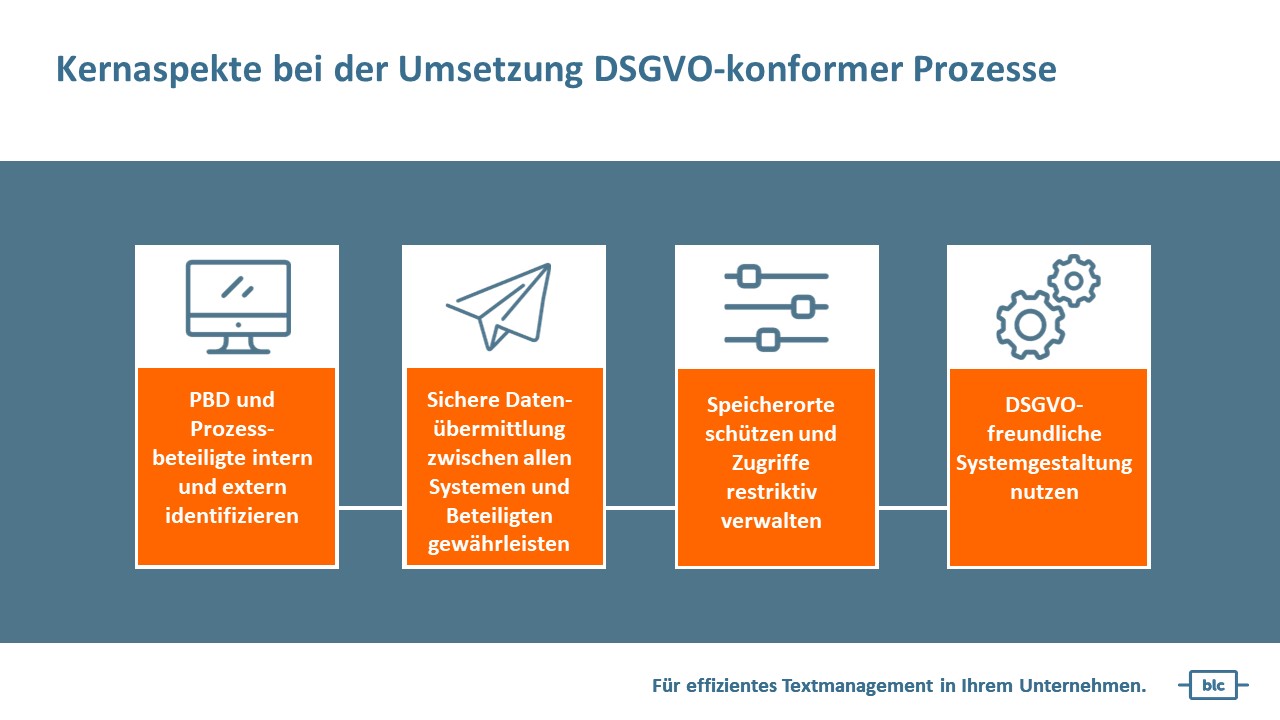
berns language consulting ist beratend für Industrieunternehmen tätig, die großvolumige Content- und Übersetzungsprozesse fahren. Diese Unternehmen sind verpflichtet, sich um die DSGVO-Compliance zu kümmern. Hier wachen viele Datenschutzbeauftragte gewissenhaft über die Einhaltung der DSGVO-Pflichten. In der Regel wird in diesen Unternehmen eine Risikoanalyse durchgeführt, die den Fluss der PBD festhält und die Eintrittswahrscheinlichkeit von Datenschutzverletzungen sowie die Schwere des Risikos für persönliche Rechte und Freiheiten beurteilt. Auf dieser Basis werden dann geeignete technische und organisatorische Maßnahmen (sogenannte TOMs) getroffen. Und davon hängt dann ab, was im Übersetzungsprozess und in den eingesetzten Systemen getan werden muss.
Cliff Hanger
Wenn also Industrieunternehmen im großen Stil Übersetzungsprozesse fahren und hier z.B. Benutzerdaten lange Jahre in Translation Memories speichern, dann müssen sie dafür sorgen, dass die PBD in diesen Prozessen DSGVO-konform behandelt werden. Das bedeutet Löschfristen einhalten oder Anonymisierung durchführen. Und zwar massenweise. Da würden DSGVO-freundliche Systeme und Funktionen sehr weiterhelfen.
Wie sind denn aktuelle Übersetzungssysteme in diesem Zusammenhang zu beurteilen? Wo sind wirkliche personenbezogene Daten im Übersetzungsprozess?
Das und mehr erfahren Sie in unserem nächsten, spannenden Blog von Christiane Spooren. So stay tuned!
Anmerkung: Wir sind keine Juristen sondern Prozessberater und freuen uns über alle Anregungen zum Thema. Die Aussagen und Interpretationen zur DSGVO sind natürlich ohne Gewähr!
