
Kerstin Berns hat im letzten Blog der DSGVO-Reihe den Bezug zwischen den wichtigsten Grundsätze der DSGVO und Übersetzungsprozessen hergestellt. Nun gehen wir einen Schritt weiter in die Praxis und schauen uns an, wie diese Grundsätze mit aktuellen Übersetzungssystemen umgesetzt werden können und welche Lösungen die Hersteller schon haben.
Wo verstecken sich personenbezogene Daten (PBD)?
PBD können in einem CAT-Tool an folgenden Stellen gespeichert werden:
- im zu übersetzenden Text selbst und der Übersetzung dieses Texts (sichtbar)
- in den Metadaten (versteckt)
- bei Workflow-Systemen in den Stammdaten
Metadaten sind Informationen zu Bearbeitungen, die das System automatisch abspeichert. Dazu gehören zum Beispiel Name oder ID des Erstellers oder Bearbeiters (das können Projektmanager, Übersetzer, Reviewer etc. sein). Metadaten werden gespeichert in:
- Übersetzungseinheiten
- Translation Memory (TM)
- Terminologie
- bei Workflow-Systemen in Reports, Log-Dateien, Rechnungsdaten
- toolabhängig in Zusatzfunktionen wie Kommentare, Track Changes, Wörterbücher etc.
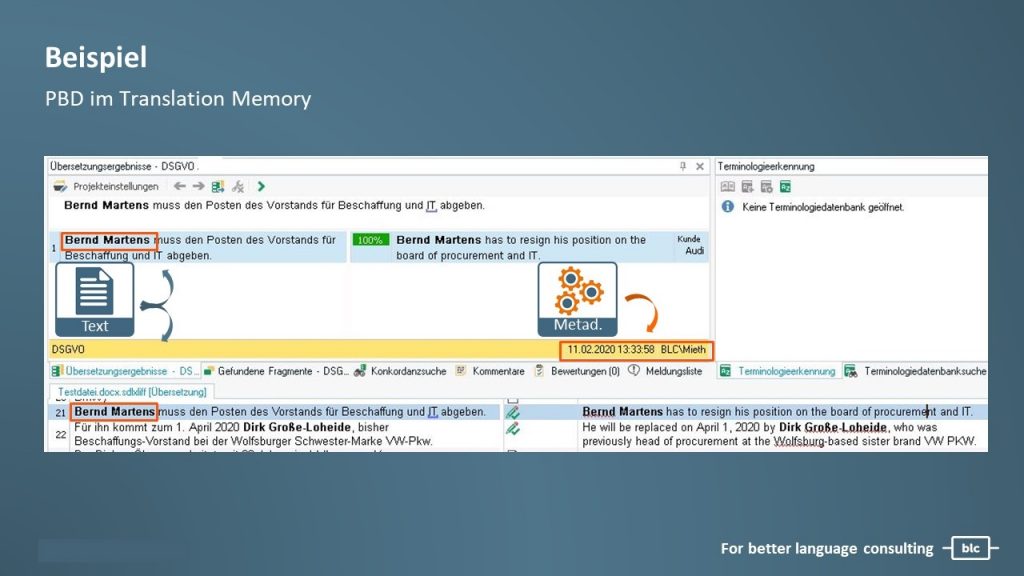
Die Crux an der Sache: Wie können PBD verlässlich gefunden werden?
Mal angenommen, wir arbeiten schon viele Jahre mit unserem CAT-Tool und haben eine beachtliche Datenmenge angesammelt (die allesamt nicht anonymisierte PBD enthält). Gemäß DSGVO müssen wir in der Lage sein, diese PBD auf Nachfrage a) lückenlos ermitteln zu können, b) vollständig exportieren zu können und c) löschen zu können. Das ist aber gar nicht so einfach!
PBD in Metadaten
PBD in Metadaten zu löschen, mag vergleichsweise einfach erscheinen. Die meisten Tools bieten die Möglichkeit, Datensätze aus dem Translation Memory (TM) nach einem bestimmten Bearbeiter zu filtern und diesen Filter beim Export anzuwenden. Je nachdem, wie diese TMs verwaltet werden, kann das in großem manuellen Aufwand münden. Bei Terminologie-Daten gibt es häufig noch nicht mal einen Filter. Und überhaupt: Wenn die Bearbeiter alle anonymisiert werden, kann bei einer Reklamation nicht mehr nachvollzogen werden, wer z.B. einen Übersetzungsfehler begangen hat. Also müsste eine Anonymisierung über ver- und entschlüsselbare oder sprechende IDs geschehen. Aber ist das überhaupt umsetzbar?
PBD in Textinhalten
Deutlich schwieriger sieht es mit PBD in den Texten selbst aus. Denn wir wollen ja, dass die PBD in der Übersetzung steht – nur im System sollen sie nicht abgespeichert werden. Also müssen sie im System anonymisiert sein, außerhalb aber nicht. Dann würden sie beim Import ins Tool durch einen Alias, Platzhalter etc. und beim Export wieder durchs Original ersetzt. Warum ist das denn so schwer?
- Die PBD sind oftmals inhaltsgebend. D.h. löscht man sie aus dem Text, versteht der Übersetzer vielleicht den Sinn nicht mehr.
- PBD haben eine grammatikalische Form, die ohne Bezugswort in der Übersetzung nicht immer übernommen werden kann.
- Bei der Ersetzung der PBD können Fehler passieren, sodass nicht alles oder zuviel ersetzt wird. Das führt zu Qualitätseinbußen in der Übersetzung.
- Man kann die PBD in den Texten nicht verlässlich finden. Bei E-Mail-Adressen mag das über reguläre Ausdrücke noch gehen, aber schon bei Telefonnummern oder Ortsangaben wird es schwierig. Und bei Eigennamen bräuchte man entweder einen ausgeklügelten Prozess über Named Entity Recognition (NER), Part-of-Speech-Tagging (PST) oder ein eigens entwickeltes Skript bzw. eine Liste aller Namen, die im Text auftauchen.
Und wer hat das schon?
Alles in allem ist die Ermittlung und Anonymisierung von PBD in den Textinhalten super unsicher und risikobehaftet.
Und was machen die CAT-Tool-Hersteller nun?
Gerade das Thema PBD in Textinhalten ist ein rotes Tuch für die Hersteller von CAT-Tools. Einige argumentieren, dass die Textinhalte, die ins Tool laufen, Sache der Textersteller sind. Will heißen: Wer PBD ins Tool schickt, ist selber schuld. Andere sagen, die Texte müssten schon anonymisiert ins Tool kommen, also durch die Textersteller anonymisiert werden. Wieder andere schlagen eine Übersetzung gänzlich ohne TM vor, wodurch aber höhere Übersetzungskosten (durch weniger Vorübersetzung) entstehen würden. Und einige wenige bieten zwar die oben beschriebene Möglichkeit an, PBD im Text zu ersetzen, aber die Nachteile bleiben bestehen. Klingt alles nicht so rosig!
Zur Behandlung von PBD in den Metadaten hingegen gibt es einige gute Ansätze, um nur einige Beispiele zu nennen:
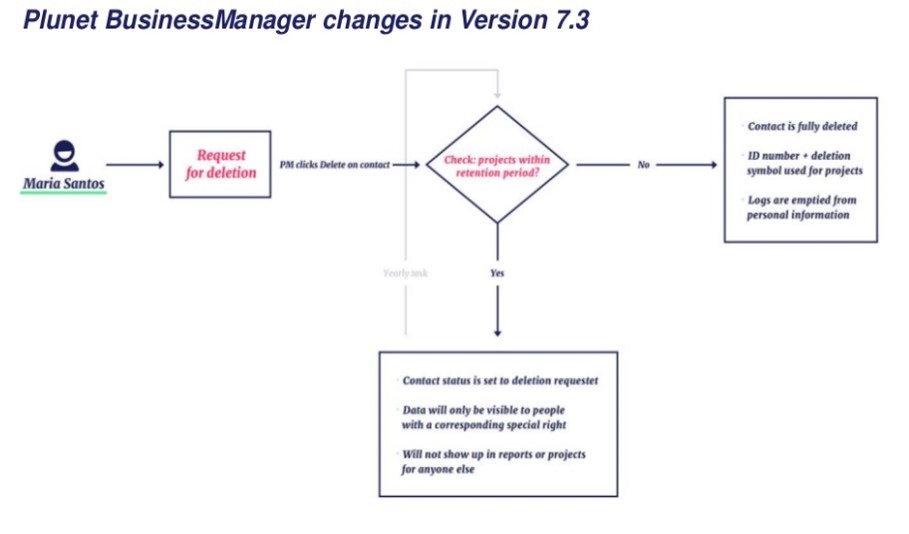
- Bei Plunet wird die Sichtbarkeit eines Kontakts bei einer Löschanfrage in laufenden Projekten automatisch eingeschränkt für Benutzer mit bestimmten Rechten.
- XTM arbeitet per se nur mit Alias statt echten Benutzernamen, sodass keine Echtnamen in den Metadaten gespeichert werden. Die Entschlüsselung des Alias erfolgt über das Benutzerkonto.
- SDL MultiTrans bietet ein umfangreiches Rollen-Rechte-Konzept, das die Sichtbarkeit der User-IDs steuert. Außerdem können hier temporäre, generische User genutzt werden, die nur für die Dauer eines Projekts im System gespeichert und nach Projektabschluss automatisch an allen Stellen gelöscht werden.
- Auch bei SDL MultiTerm Workflow können statt Usernamen von Vornherein Gruppennamen oder Rollen verwendet werden. Usernamen werden hier zudem auf Nachfrage aus allen Log-Files, Abstimmungshistorien etc. gelöscht bzw. anonymisiert.
Als Nächstes ein Fallbeispiel
Man kann also sagen, dass die Umsetzung der DSGVO in Übersetzungssystemen grundsätzlich schwierig und für die Textqualität alles andere als förderlich ist. Dennoch gibt es einige Lösungen, vor allem was den Umgang mit personenbezogenen Daten in System-Metadaten angeht. Ein größeres Problem stellen dagegen PBD in den Textinhalten dar.
Im nächsten und letzten Teil möchten wir noch einen Schritt weiter in die Praxis gehen und ein Fallbeispiel vorstellen, das mithilfe von SDL Trados Studio und dessen DSGVO-Lösungsansätzen bearbeitet wird. Es bleibt also spannend!
