
Seitdem das deep learning in die Welt praktizierter maschineller Lernverfahren Einzug gehalten hat, vergeht kaum eine Woche, in der man nicht von Durchbrüchen und neuen Anwendungsfällen neuronaler Netze lesen kann. Im heutigen Blog möchten wir Ihnen einen kleinen Einblick in unsere Schulungen zur digitalen Qualifizierung und das Modul „Maschinelles Lernen“ geben.
Bei der Bilderkennung und -generierung, der maschinellen Übersetzung oder der Klassifikation beliebig großer Datenmengen unterstützt das deep learning den Menschen in immer mehr Lebensbereichen von der Medizin über IT-Sicherheitsanwendungen bis hin zur Planung komplexer logistischer Abläufe in Verkehr und Produktvertrieb. Bei aller Aufmerksamkeit, die den neuronalen Netzen aktuell zukommt, werden klassische Ansätze des maschinellen Lernens oft vergessen. Im Rahmen unserer Schulungen zur digitalen Qualifizierung gehen wir auf Unterschiede und Vorzüge der Verfahren hinter dem maschinellen Lernen ein.
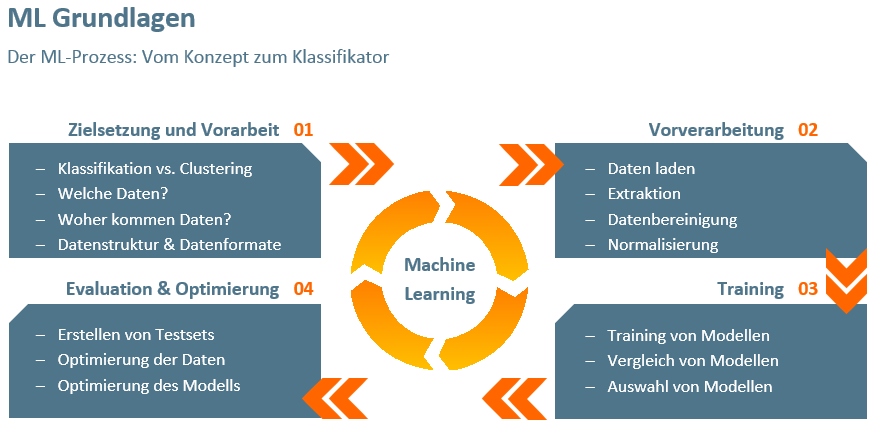
Von Bildern zu Vektoren
Die Terminologie der neuronalen Netze lässt den Neuling oftmals zunächst ratlos zurück. Was sich hinter den meist englischen Begrifflichkeiten wie Torch, Tensorflow, LSTM, attention mechanism, Hyperparametern, backpropagation, Optimizern und Epochen verbirgt und wie diese zusammenspielen, um Katzen in Bildern zu erkennen und Krankheitswahrscheinlichkeiten anhand von Patientendaten vorauszusagen, ist zunächst schwer zu durchdringen. Dabei ist das Verfahren, das den unterschiedlichen Klassifikationsaufgaben zugrunde liegt, doch immer sehr ähnlich:
Am Anfang steht ein neuronales Netz, bestehend aus künstlichen Neuronen (Knoten), die in mehreren Ebenen (Layern) angeordnet und untereinander über Kanten vernetzt sind. Die Magie der neuronalen Netze besteht dabei in der eigenständigen Anpassung von Gewichtungen, die mit diesen Verbindungen zusammenhängen. Ziel des Trainings ist die Optimierung dieser Gewichtungen und die damit einhergehende Minimierung des Fehlers bei der Datenklassifikation.
Beim Training neuronaler Netze verarbeitet das System nun Eingangssignale (z. B. Bilder von Tieren oder Sätze in einer Ausgangssprache) und wandelt diese in interne Repräsentationen (Zahlenvektoren) um, mit denen Berechnungen durchgeführt werden können. Über mehrere Durchläufe (Epochen) der Daten durch das Netz lernt dieses dann, wie die Gewichtungen im Netz verteilt sein müssen, sodass am Ende die gewünschten Ergebnisse (die Art des Tieres oder eine bestimmte Wortfolge in der Zielsprache) herauskommen. Was diese gewünschten Ergebnisse sind, weiß das Netz anhand des Trainingssets. Dieses bildet die Wissensgrundlage des deep learnings und beinhaltet eine möglichst große Menge von Datensätzen, zu denen die korrekten Resultate (Tierarten oder Sätze) bekannt sind.
Die Kunst beim Training neuronaler Netze liegt in der Konfiguration der zahlreichen Hyperparameter, die z. B. die Anzahl der Neuronenschichten (Layer) und die Optimierungsalgorithmen festlegen, als auch in der Erfahrung mit bestimmten Anwendungsfällen und den mit ihnen verbundenen Daten. Je nach Fall kann die Erstellung eines guten Modells einige Zeit in Anspruch nehmen. In Abhängigkeit der Art der Daten haben sich verschiedene Netzwerktypen (z. B. Recurrent Neural Networks für die maschinelle Übersetzung) durchgesetzt, die in diversen Programmbibliotheken (Frameworks) für gängige Programmiersprachen vorliegen. Die Frameworks wie Torch oder Tensorflow unterscheiden sich dabei vor allem in der Einstiegshürde und dem Grad der Unterstützung durch die Community der meist unter Open Source Lizenz stehenden Pakete.
Neben der Technik entscheidet vor allem der Umfang und die Qualität der Datenbasis darüber, ob das resultierende Klassifikationsmodell den Ansprüchen genügt. Sind die Daten qualitativ nicht ausreichend, müssen ggf. hohe Aufwände für die Datenbeschaffung und/oder Bereinigung einkalkuliert werden. Was hierzu nötig ist, ist Thema unseres Schulungsmoduls ‚Ressourcen und Datenaufbereitungen für maschinelle Lernverfahren.‘
Von Notebooks zu Mietpreisen
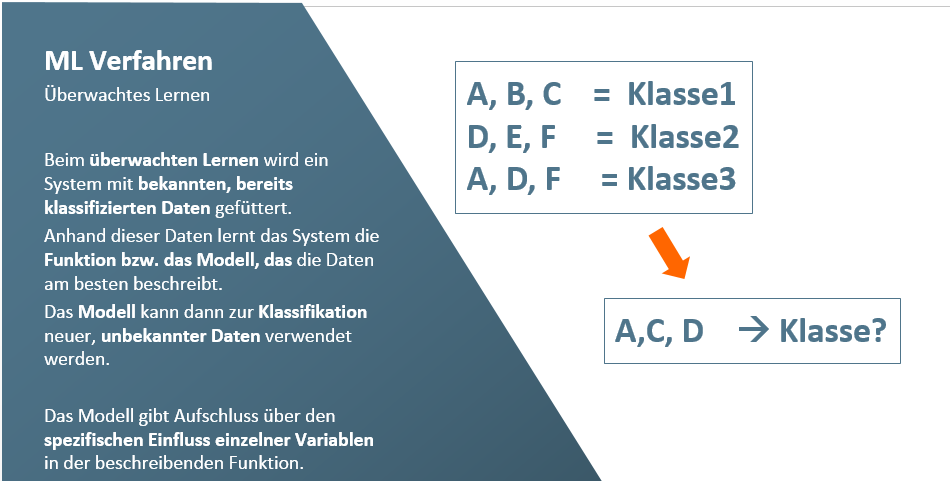
Neben neuronalen Netzen können zur Datenklassifikation noch eine Reihe weiterer Verfahren angewendet werden. Zu diesen ‚klassischen‘ Methoden gehören zahlreiche Algorithmen, die allesamt (wie auch das deep learning) dem Bereich des überwachten Lernens zuzuordnen sind. Überwacht heißt in diesem Zusammenhang lediglich, dass wir für das Training möglichst viele Datensätze benötigen, zu denen die gewünschten Klassifikationen (auch: Labels) bekannt sind. Genau wie beim deep learning werden die Zusammenhänge in den Daten gelernt und auf neue, bisher ungesehene Datensätze generalisiert. Je nachdem, ob konkrete Klassen (Katze vs. Hund auf einem Bild) oder ein Wert (Mietpreise in Abhängigkeit von Wohnort, Quadratmeterzahl, etc.) vorhergesagt werden soll, kommen entweder Klassifikations- oder Regressionsverfahren zum Einsatz. Dazu gehören Verfahren wie Entscheidungsbäume, der Satz von Bayes, Support Vector Machines und Spielarten der linearen Regression. Hierzu gibt es eine Reihe von Programmbibliotheken, die vor allem im Umfeld der Programmiersprache Python zu finden sind. Daneben gibt es mit R, Weka und den Cloud-Lösungen von Microsoft, Amazon & Co. zahlreiche Plattformen, um eigene Projekte umzusetzen.
Für viele Anwendungsfälle ist es nicht erforderlich, die mit hohen Hardwareanforderungen verbundenen Verfahren des deep learnings auszureizen. Nach einer Analyse aller Variablen für eine Klassifikationsaufgabe können auch weniger aufwändige Verfahren durchaus zum Ziel führen. Kleinere Übungsprojekte lassen sich z. B. völlig kostenfrei mit den Microsoft Azure Notebooks durchführen. Die Notebooks erfordern lediglich eine gültige Microsoft ID und einen Webbrowser – grundlegende Module für das maschinelle Lernen sind in der Cloud bereits vorinstalliert und man kann sofort loslegen.
Die blc-Schulungsmodule
Sind Sie neugierig geworden, wie maschinelles Lernen funktioniert, und möchten Sie wissen, welche Möglichkeiten maschinelles Lernen für die Klassifikation von Textdokumenten birgt? Möchten Sie praktische Einblicke in die Verfahren und Aufwände bei der Datenaufbereitung für maschinelle Lernverfahren bekommen? Gerne geben wir Ihnen auf Anfrage weitere Einblicke in diese und weitere Schulungsmodule zur maschinellen Übersetzung und Speech2Speech-Technologien.
Beitragsbild von Andy Kelly auf Unsplash.



